编程中的元工具
- 调试器(debugger)
- 包管理器(package manager)
- 构建系统(build system)
- 链路跟踪,性能分析等(tracer, profiling tools)
- 张量-编译器(tensor compiler)
内容讲解
如何创建一个便利,强大,高效C++,Python编程的学习,开发环境
工具包括:
python package manager
- import/module system
- packaging solution
Docker(较新版本)+wsl2
- docker ce
- 有一个对应的docker镜像
conda
vscode
jupyter notebook(cling+clang)
gdb
cython
chatgpt
Docker创建开发容器
基于wsl2的docker容器(可以使用GPU)vscode + docker container
使用Cling学习C++
- Cling+MS,Learncpp教程的组合(语法+词法学习)
- 讲解Cling如何导入库
- 使用Cling探索bigInt
- Cling结合探索CUDA
Cling背后的原理
- 讲解LLVM,Clang的背景和工具意义
- Cling软件架构,运行视图
超强内存分析工具Memray
- Memray基本使用(参考文档)
- Memray分析推理框架工作时的堆内存
- Memray工作原理
用GDB调试Memray和其他Cython开发的软件
- 确保编译的动态库带有调试符号
- rbreak来打断点
- 结合Python脚本来更好地分析Tracker中的代码
GDB从入门到精进
- GDB基本用法
- GDB结合Python,更强的调试工具
- GDB多线程案例
- PDB工具
TVM编译算子库 *
termux
作为提供tab生产力,我们需要好好研究下这个工具
机理
termux属于终端模拟器,使用"execve"系统调用并重定向标准输出的方法来工作。多数的安卓终端模拟器只具备非常少的权限,但在termux上,你能运行绝大多数的GNU软件。 首先,termux并不是虚拟机。所有提供的软件包都通过安卓NDK交叉编译,由于缺少完整的文件访问权限,termux并不能将文件放置在诸如/bin,/usr这样的路径,而是统一放在了/data/data/com.termux/files/usr,这个路径被称为"prefix",环境变量里的"$PREFIX"也是这个路径。注意这个路径不能被更改,因为:
- 文件系统必须支持unix权限和特殊文件,如符号链接
- 该前缀路径在termux项目中被硬编码了(没错,termux是开源的)
termux不符合FHS标准
这就是termux不使用Debian或者Ubuntu作为标准环境的原因了。Filesystem Hierarchy Standard是LINUX基金会制定的标准unix系统所需要满足的约定。因此termux上的应用都需要在特定环境重新编译一次。不过这个问题还是比较好解决的
是否需要root
如果你想做下面这些事,那你需要root:
- 修改设备固件
- 修改内核参数
- 全部文件的读写权
- 对硬件设备模块有直接访问权限
termux-desktop
修改密码
如果忘记了一开始设置的密码在,在termux中使用
vncpasswd可以修改相关密码
包管理器/构建系统
依赖管理
编程语言的module system
考虑自己去设计一个模块系统,会发现设计空间是很大的。模块可能是由文本组成的(C),也可能是运行时的代码(Python),不妨想象一个简化版本的模块系统,很多问题会变得简单:
- 一个文件 = 一个模块
- 文件的名字 = 模块的名字
- 目录 = 项目
对于强类型,静态编译的语言,如C/C++,一般可以使用doxygen来导出相应的依赖关系,文件结构与逻辑结构的对应关系会更加明显直接,并且更容易处理和分析。
python的module系统
本模块会用一个demo项目pydemo来说明/演示python模块系统的一些细节
一些要点:
- Python的import机制是一种延迟加载机制,只有在需要访问模块中对象的时,才会进行加载和执行
- Python支持动态导入模块,使用importlib来动态加载模块
- 搜索模块:Python会在当前目录,Python标准库目录,环境变量中PYTHONPATH指定的目录,第三方库目录,但是只要记住统合起来都会在"sys.path"中进行搜索
- 编译模块:当搜索到了要导入的模块,Python解释器会将其编译为字节码文件(pyc或pyo文件),保存在__pycache__目录中
Python当中的模块对应到的是一个以py为后缀名的源码文件,Python还有一个语言特定的概念,包(Package),首先:包也是一个模块,包可以包含子模块或者是子包,包也是一个有__path__属性的模块,创建一个包的方式是,新建一个目录,然后在目录中创建__init__.py,当这个包被当做模块导入时,__init__.py中的内容便是会被导入的内容。
更准确的来说,是自动导入
比如导入pydemo之后,hubei被自动导入,但是guangdong却没有,关键就是在于根目录中的__init__.py
# 建议在交互式环境中测试一下
import pydemo
# output: <module 'pydemo.hubei' (<_frozen_importlib_external._NamespaceLoader object at 0x7fa22b15d150>)>
pydemo.hubei
# AttributeError: module 'pydemo' has no attribute 'guangdong'
pydemo.guangdong当你import一个包的时候,包的子模块和子包并不会被导入,你需要在__init__.py中将这些模块导入进来(直接通过import xxx的方式无法导入)。
但是你可以通过"from package import submodule"(subpackage)的方式去显式地导入子模块
需要记住的事:当你导入一个模块,你会创建一个新的命名空间并把模块中的内容load进这个命名空间中,命名空间是基于Python的字典数据结构实现的,可以通过module.__dict__的方式来访问具体的对象
绝对导入和相对导入是一个需要引起注意的问题,比如你在外层目录(root-package)对子目录(sub-package)的模块进行引用时,如果子目录中的模块之间也存在引用关系,一不注意就容易引发"Module Not Found",使用相对导入可以一定程度上解决这个问题:
from . import xxx当然,这种办法也会带来一些问题,比如当你去直接执行使用相对导入的文件时,会触发提醒“ImportError: attempted relative import with no known parent package”,这是因为使用了相对引入的文件的resolved规则在脚本和模块中是不一样的。
好好利用importlib,可以实现自己的导入机制。我们先来分析下importlib的关键用法
先来对importlib讲解的内容做个分类:
- 实现定制化的
import本身(更细致地说,实现finders, loaders, importer) - reload
- import和__import__现在的实现本身(3.3更新内容之一)
- 3.8新特性:metadata
有了importlib,你可以import everything
简单来说,importlib提供给用户修改import原语的能力
你甚至可以用这种方法高效地导入stackoverflow上的优秀代码
在相关机制的利用层面,我觉得最优秀的实践就是xonsh,一个将shell和python有机混合在一起的生产力工具,对于Python开发者而言,这应该就是最好用的shell了。 下面我们来仔细瞧瞧xonsh工具是如何使用以及如何利用importlib的
 通过这张图大家就能知道,Xonsh是把shell和python这两种语言混在一起形成了一种新的超集语言(即xonsh),通过xonsh:
通过这张图大家就能知道,Xonsh是把shell和python这两种语言混在一起形成了一种新的超集语言(即xonsh),通过xonsh:
- 你可以在命令行中定义Python的class,function,同时你可以利用shell到的应用加载器,环境变量等
- 上面提到的能力意味着shell本身是"可编程的",你可以结合shell本身的功能和Python语法创造出自己的命令—这本身就是一种定制shell的过程
- 配合cppyy这样的动态binding工具,最终可以将高性能的计算能力和高效开发环境结合,成为开发者的最佳toolchain
我们通过一些例子来演示:
那么,xonsh之下的魔法到底是什么呢?
我总结了一下,主要是这些:
- 使用
importlib实现了xonsh语言的Import系统 - parser技术
- subprocess stream的处理
xonsh的解析模式可以简单看成python-mode和subprocess-mode的结合。具体的,我们可以看下:
# this will be in subproc-mode, because ls doesn't exist
>>> ls -l
total 0
-rw-rw-r-- 1 snail snail 0 Mar 8 15:46 xonsh
>>> # set ls and l variables to force python-mode
>>> ls = 44
>>> l = 2
>>> ls -l
42
>>> # deleting ls will return us to subproc-mode
>>> del ls
>>> ls -l
total 0
-rw-rw-r-- 1 snail snail 0 Mar 8 15:46 xonshreload函数可以完成插件化的模块设计
使用metadata的一些典例:
from importlib import metadata
from pprint import pprint
# 将元信息的列表展示出来,元信息本身是dict的数据结构
list(metadata.metadata("pandas"))
# 列举项目的模块路径
pprint([p for p in metadata.files("pandas") if p.suffix == ".so"])
pprint([p for p in metadata.files("pandas") if p.suffix == ".pyx"])Python项目结构的典例。我希望通过下面这些知名项目来介绍典型的文件组织结构:
标准库
- asyncio
第三方库
- FastAPI(纯Python项目,Web框架)
- memray
- annoy(高效算法的精简binding)
- thinc(层次分明的深度学习框架)
asyncio
asyncio的文件组织是:
asyncio/
__init__.py
xx.py其中,init文件的大致内容如下:
# 将有__all__变量的子模块的所有内容导出
from .base_events import *
from .coroutines import *
from .events import *
# 将all导出
__all__ = (base_events.__all__ + coroutines.__all__ + ...)
if sys.platform == 'win32':
from .windows_events import *
__all__ += windows_events.__all__
else:
from .unix_events import *
__all__ += unix_events.__all__去分析源码,能看到的是,一些没有暴露接口的子模块,如log.py,一般是处在整个依赖关系中的最底层。__all__指明了那些会被导出的符号,但是请注意,这种声明,只会影响到那些通过from <module> import *的场景,即是说那些没有被包含的符号也可以通过from xx import xx的方式来导出。
FastAPI
c/c++的include系统
distributing/setup
安装Python软件包
我们大多使用pip来安装pypi上的软件包,软件包以两种形式存在:
- source distributions
- wheels 如果pypi上两种资源都存在,pip会优先选择wheel,wheel是一种预编译的发行包,它会包含编译好的二进制扩展(其实wheels设计之初就是为了更好的屏蔽二进制扩展后工具链的复杂性)。 wheels是在PEP 427中被提出的,下面的内容是对关键信息的提炼。
首先,wheels文件实质上是一种ZIP格式的以.whl作为后缀的文件扩展。wheel安装最大的优点是快速,简单且暴力,安装过程可以细化为两个步骤,Unpack以及Spread: 下面以distribution-1.0-py32-none-any.whl的安装过程为例:
- Unpack
- 解析dist-info中的WHEEL文件
- 首先验证wheel版本和安装器是否兼容。
- 如果
Root-IS-Purelib == 'true',将文档解压至(purelib)site-packages - 上述条件不满足,解压至
(platlib)site-packages
- spread
- 被解压的文件中包含
distribution-1.0-info和(如果有的话)distribution-1.0.data
- 被解压的文件中包含
wheel文件中包含的内容有:
- WHEEL中指定的purelib和platlib路径下的
{distribution}-{version}.dist-info/包含元数据- METADATA:
- RECORD:
- WHEEL:
- WHEEL-Version
- Generator: 构造这个文档的工具
- Root-Is-Purelib:略
- ``
关于purelib和platlib,不同平台的路径不一样,对于unix类平台下的路径,纯PY文件一般是在/usr/lib/pythonX.Y/site(或者是dist)-packages,平台相关的文件则是在/usr/lib64/pythonX.Y/site-packages下,但是要注意,so文件一般也都是在/usr/lib/pythonX.Y/site-packages中。
打包Python
首先这一部分的内容大家可以在两个官方文档下获取相关的资源:
学习打包Python应用,我们主要就是要学:
- 打包Python应用所必须得工具有哪些
- 一个项目要能够打包并进行分发,得考虑哪些关键问题
- 如果项目中使用到了C/C++作为子项目或者是项目的一部分,该如何打包
Python应用已经渗透进了不同领域。
python项目的打包流程方案的提出是通过PEPs(Python Enhancement Proposals)达成的,而方案的实现则是交给了PyPA(Python Packaging Authority)。相关的PEPs有这些:
- PEP 427 描述了wheels文件是如何被打包的
- PEP 440 描述了版本号是如何被解析的
- PEP 508 描述了依赖关系是如何被处理的
- PEP 517 描述了"build backend"是如何工作的
- PEP 518 确立了"build system"的内容
- PEP 621 描述了项目元信息应该包含哪些内容
- PEP 660 描述了可编辑安装(editable installs)是如何使用的
一个标准的Python项目一定需要包含的内容是:
- pyproject.toml
- 指定的build system
让我们了解一下通用Python项目的打包方法。 首先,在最外层目录创建setup.py以及setup.cfg文件,这两个文件的最简化表示如下:接下来在该目录下,使用
python -m pip install -e .从PEP-621开始,python社区统一选择pyproject.toml作为项目元信息的标准,setuptools也支持了这一标准,那么问题是两者的依赖关系究竟是怎么样的。简单来说,是setuptools依赖于pyproject.toml,具体的,跟setuptools相关的主要是[build-system]和[project]两项信息。
python项目的标准配置文件是pyproject.toml,这份配置中,使用者需要在[build-system]表中指定构建工具,常用的构建工具包括:flit,hatch,pdm,poetry,setuptools, 我们至少得会使用setuptools,这项工具被大多数的大型项目用来作为默认的构建工具(build backend)。
展示一份标准的pyproject.toml:
[build-system]
requires = ["setuptools", "setuptools-scm"]
build-backend = "setuptools.build_meta"
[project]
name = "example_package_YOUR_USERNAME_HERE"
authors = [
{name = "xxx", email = "xxx@xx.edu"},
]
description = "My package description"
readme = "README.rst"
requires-python = ">=3.7"
license = {text = "BSD-3-Clause"}
# 摘自FastAPI
dependencies = [
"starlette>=0.27.0,<0.28.0",
"pydantic>=1.7.4,!=1.8,!=1.8.1,!=2.0.0,!=2.0.1,!=2.1.0,<3.0.0",
"typing-extensions>=4.5.0",
"anyio>=3.7.1,<4.0.0",
]紧接着考虑写一份完整的pyproject.toml,你需要考虑的内容包括这些(由于不同构建工具对应的字段头不一样,我们这里用setuptools来做例子):
- 有哪些package,它们在哪 -> [tool.setuptools.packages]
我们进入到实践环节,首先最常见的,当我们有一个Python应用(application),我们要如何打包,按照我自己的经验,主要是下面几部:
- 项目文件结构规整化,注意这些目录/文件
<project_name>- 存放源码的地方,源码所体现的模块的逻辑结构不再陈述,复习请回到前文的import系统- .gitignore, LICENSE.txt, README.md - 项目附带文件
- docs - 存放相关文档的路径
- config - 项目配置文件
- setup.py, requirements.txt - 安装脚本
- 处理依赖项
- 如果有扩展代码,则需要完成对应的extension(setup.py)
- 对于依赖的第三方库,可以使用
pipreqs这样的工具自动resolve项目的依赖项,从而生成requirements.txt - 完成setup.py,包括一些项目元信息的配置
- 测试setup.py
一篇关于处理依赖关系的比较好的答案: stackoverflow-49689880 重点看下pip-compile的内容
setup.py的背后
对于开发者而言,一定需要了解最通用的安装方案。setuptools强大的点可以概括为如下几点:
- 使用广泛:Setuptools是Python
distutils包的增强版,distutils是Cpython内置的官方构建工具,现在在逐步淘汰中 - 自动地搜索所有相关文件,并将它们包含到项目树中
- 支持Cython,可以搜索并找出pyx文件
- 支持开发者模式,可以直接修改源代码调试
- 对PEP420
find_namespace_packages()的全面支持
我们先从如何写一个稍微有些复杂项目的setup.py开始,介绍python的打包过程
下面我以两个混合编程的项目(cython)作为例子,来讲解一个项目的打包和分发
首先是pandas,pandas是一个典型的cython加速库,从该项目的"setup.py",我们能学到不少东西(一些tricks),我们来梳理该文件的重要内容(提交54497中):
- 首先项目使用的是setuptools的build_ext方法, 然后对调用的方法简单地进行了封装,从而在构建过程中能够render_template(前提是安装了cython)
- 接着我们看pandas项目中对单个Extension的封装:变量声明在547行,单个obj的装载在434 -> 581行,结构如下:
# depends单独列举(头文件或_pxi_dep),sources是单个pyx文件的路径,include在_libs/include下,
Extension(
f"pandas.{name}",
sources, depends, include,
include = ["pandas/_libs/include", numpy.get_include()],
extra_compile_args = [],
extra_link_args = [],
)- cmdclass中关键的"build_ext"字段,是继承于build_ext的一个class,会在build_ext之前,执行check_cython_extensions方法来确保pyx源代码确实存在:
def check_cython_extensions(self, extensions):
for ext in extensions:
for src in ext.sources:
if not os.path.exists(src):
print(f"{ext.name}: -> [{ext.sources}]")
raise Exception(
f"""Cython-generated file '{src}' not found.
Cython is required to compile pandas from a development branch.
Please install Cython or download a release package of pandas.
"""
)- setup方法显然是从setuptools处获取的
另外我们再来看,我的示例项目hpds的源码结构以及native模块的引用位置:
hpds
acclerate # 依赖pybind11和cuda
concurrent # 依赖C++的std algorithm-cython
wrapper # 依赖.c中的函数-cython项目中后两项是依赖于cython的,因此setup.py可以参照pandas项目的构建逻辑来编写。而pybind11,我们可以从官方文档里找到答案(当然cython也一样):https://pybind11.readthedocs.io/en/stable/compiling.html,
这里,我们发现一个问题:pybind自带的Pybind11Extension并不支持.cu文件的编译(毕竟编译cuda代码使用的其实是nvcc编译器),因此,这一步,无论用什么方法,似乎都无法逃脱cmake。
CMake/make系统
之前已经简要介绍过了CMake的作用。我们以unix下的安装过程举例,一般安转一个软件包,安装的内容包括:
- 可执行文件(bin)
- 头文件(相当于对外暴露的接口,include)
- 库文件(lib)
- cmake文件(share/package) 安装的内容普遍是安装到"prefix"下(通常是/usr/local)
构建系统
构建系统是和语言强绑定,我们主要看C++,python这两个语言的一些项目和常规方法
开发容器管理
一个可随时迁移,并同步的开发环境是非常重要的。
相关工具集
- chroot
- vagrant
- container
- lxc rootfs
- Nix
理念
可以看看vagrant作者对于隔离环境的看法:看法 实际上vagrant不应该和docker本身比较,而是和Boot2Docker(一个可以运行Docker的最小操作系统)
Portable Development-environment
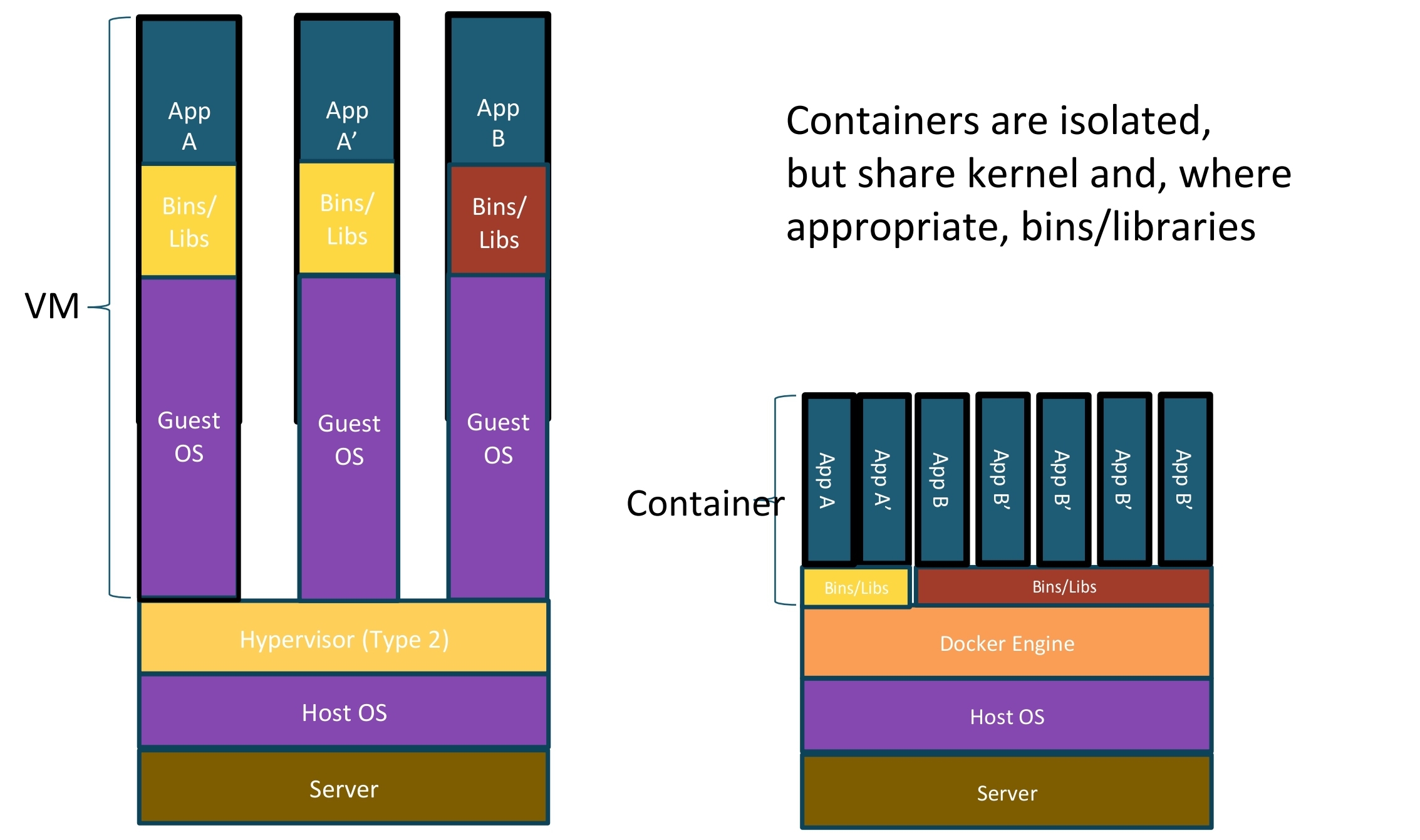
工具应该具备的特性:
- flexibility
- reproducible results
- 能够支持多种镜像格式:
- Docker Images
- CHOS Images
- vmware Images
前菜:通过bocker了解docker
了解btrfs
简言之是"Better FS",suse和fedora的默认文件系统,具备这些特性:
- 创建快照
- copy on write:与其覆写,不如拷贝
- subvolumes(有点像分区,partitions++)
- checksums:可以保证数据完整性
缺点:
- 不要用RAID(和标准的RAID不一样)
深入介绍容器技术
了解容器技术我认为最终要的几个关键词:
- Namespaces
- 联合文件系统
- oci runtime
- linux control group
- 内核能力
Namespaces
Docker使用linux namespace技术来实现容器间的资源隔离
| Namespace | syscall | 隔离内容 |
|---|---|---|
| PID | CLONE_NEWPID | 隔离用户的进程 |
| UTS | CLONE_NEWUTS | 使每个容器有独立的hostname和domain name,使其在网络上可以被视为独立节点 |
| IPC | CLONE_NEWIPC | 保证容器间的进程交互,信号量,消息队列,共享内存的相互隔离 |
| network | CLONE_NEWNET | 实现网络隔离,每个net namespace有独立的network devices,ip addresses, ip routing tables,/proc/net目录 |
| Mount | CLONE_NEWNS | 每个namespace的容器在/proc/mounts的信息中只包含namespace的mount point |
| User | CLONE_NEWUSER | 允许每个容器有不同的user和group id |
一个问题:要区分不同的shell环境,关键是哪一个namespace的隔离在起作用(系统变量)
联合文件系统
我们会讲到:
- 什么是unionFS
- 实践:挂载overlayFS到实验路径进行讲解
- 实践:OCI image和unions的关系,探索文件系统上的机制
unionFS是一种分层,轻量级并且高性能的文件系统,它对文件系统的修改作为一次次提交来层层叠加,同时可以将不同目录挂载到同一个虚拟文件系统下。我们知道Docker镜像可以通过分层来继承,不同的Docker容器可以共享基础文件系统层,再加上自己独有的改动层,大大提高存储效率,因此该技术算得上是容器的核心技术之一。Docker支持的联合文件系统包括: aufs,btrfs,vfs,devicemapper, overlay2
联合文件系统的核心特性:
- copy-on-write
要查看当前docker所使用的文件系统可以:
docker info | grep 'Storage Driver'
# podman
podman info | grep 'graphDriverName'
# 为后面使用podman查看overlay做好准备
sudo ln -s /home/xiao-sa/.local/share/containers/storage/ /var/lib/podman下面我们以OverlayFS为例,讲解联合文件系统,首先文件系统的底层是只读的,而上层是可读写的,而展示出的层通常被称为merged/union view; 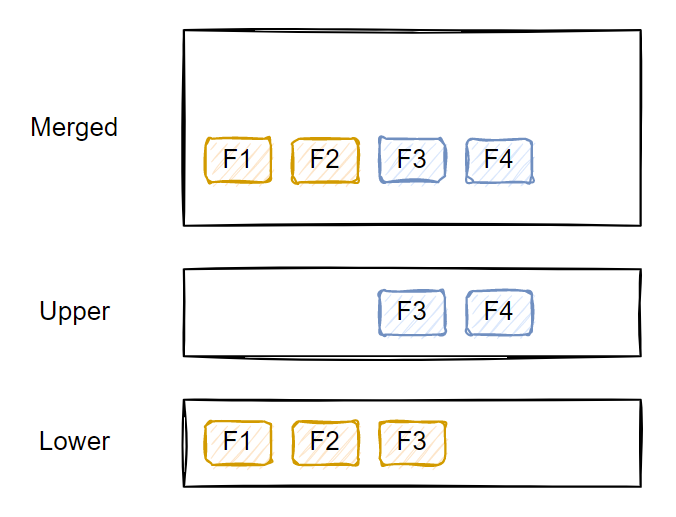
下面来实际演示一次overlayFS的实际表现
# 创建demo目录
...
# mount
sudo mount overlay -t overlay -o lowerdir=demo/lower, upperdir=demo/upper, workdir=demo/work/ demo/merged/看详细内容,请查看https://ravichaganti.com/blog/2022-10-18-understanding-container-images-the-fundamentals/
探索podman overlay
# 为后面使用podman查看overlay做好准备
sudo ln -s /home/xiao-sa/.local/share/containers/storage/ /var/lib/podman
# 查看pytorch/llvm:12.0.0下overlay的内容
podman image inspect pytorch/llvm:12.0.0 | jq -r '.[0] | {Data: .GraphDriver.Data}'
# 在文件系统中去查看
# 找一下对应关系
ll /var/lib/podman/overlay
# 新建一个container
podman run -d --name test_1 pytorch/llvm:12.0.0 sleep 100000
# 查看容器的存储层级
podman container inspect test_1 | jq -r '.[0] | {Data: .GraphDriver.Data}'
# 修改容器文件
podman exec test_1 touch /hello.txt原本的输出为:
{
"Data": {
"LowerDir": "/home/xiao-sa/.local/share/containers/storage/overlay/397004f98f9973770f8647404f684002f0d55eeba0a13ca7e107abb1f69110a4/diff:/home/xiao-sa/.local/share/containers/storage/overlay/8e012198eea15b2554b07014081c85fec4967a1b9cc4b65bd9a4bce3ae1c0c88/diff",
"UpperDir": "/home/xiao-sa/.local/share/containers/storage/overlay/9da6771510c20a3565d232b18d14d473ffcb7b56887255decfbb1f2128f8a1da/diff",
"WorkDir": "/home/xiao-sa/.local/share/containers/storage/overlay/9da6771510c20a3565d232b18d14d473ffcb7b56887255decfbb1f2128f8a1da/work"
}
}{
"Data": {
"LowerDir": "/home/xiao-sa/.local/share/containers/storage/overlay/9da6771510c20a3565d232b18d14d473ffcb7b56887255decfbb1f2128f8a1da/diff:/home/xiao-sa/.local/share/containers/storage/overlay/397004f98f9973770f8647404f684002f0d55eeba0a13ca7e107abb1f69110a4/diff:/home/xiao-sa/.local/share/containers/storage/overlay/8e012198eea15b2554b07014081c85fec4967a1b9cc4b65bd9a4bce3ae1c0c88/diff",
"MergedDir": "/home/xiao-sa/.local/share/containers/storage/overlay/3069b91a2c5d6780c6b99441d10cd7eaa6f24d805bfeca000e92e1e31faf11f7/merged",
"UpperDir": "/home/xiao-sa/.local/share/containers/storage/overlay/3069b91a2c5d6780c6b99441d10cd7eaa6f24d805bfeca000e92e1e31faf11f7/diff",
"WorkDir": "/home/xiao-sa/.local/share/containers/storage/overlay/3069b91a2c5d6780c6b99441d10cd7eaa6f24d805bfeca000e92e1e31faf11f7/work"
}
}下面是一个大致的依赖关系(注意hash值是错误的,但是只是为了说明overlay的关系)
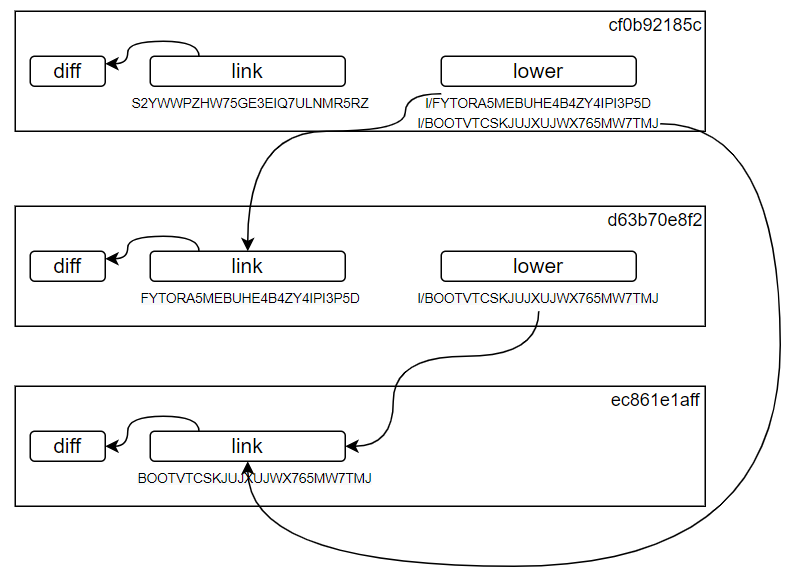
图中的layer本身是镜像的layer,所以是只读的,不可以修改的。
Docker容器存在的一个很大问题是:镜像体积在多次提交后变得过于膨胀,该怎么去面对和解决这个问题呢? 首先,为什么一般我们在交互式窗口中使用yum这类的包管理器仅仅是装了一个小工具或者库之后,体积的膨胀却超出了软件体积本身呢?
大家先得掌握一个命令:
docker history <image-id>这个命令能够看到镜像的提交历史,其中SIZE那一列的增长最终都会作用到镜像本身,因为在某一个layer提交之后的layer,其删除的磁盘空间实际仍在之前的layer被保留着。
那如何解决这个问题?我们给自己设置一个目标:制作一个满足自己需求的最小容器,其实有几种方法可以实现这个目标:
- from scratch/alpine
- 使用"-v"挂载到本地的某个rootfs
- distroless-docker
这个主题本身就有不小的研究价值,我们放到最小化容器镜像来研究
runc & OCI runtime spec
我们先来了解OCI(open container initiative)
The Open Container Initiative is an open governance structure for the express purpose of creating open industry standards around container formats and runtimes.
该组织是在2015年被Docker公司创立的,OCI当前包含三项标准:
- the Runtime Specification (runtime-spec)
- the Image Specification (image-spec)
- the Distribution Specification (distribution-spec).
第一项标准指出了如何运行一个解压好的文件系统包(filesystem bundle),一个OCI的实现,可以下载一个OCI镜像,并将它解压为一个OCI文件系统包并运行。其中,docker公司实现的runc就是一个标准的OCI runtime实现,可以作为runtime的一个标杆。
想了解具体有哪些实现,可以看这里:https://github.com/opencontainers/runtime-spec/blob/main/implementations.md
综上述,"container"概念本身其实和Docker并无直接联系,只是Docker算是应用最广泛的容器管理工具,实际上现阶段,像podman这样兴起的工具也开始扩建自己的应用市场,培养起自己的生态了,除了docker本身所支持的功能,podman还有一些看起来更优秀的特性,这个我们等会说。
容器运行时(container runtime)是实际进行环境隔离的容器运行引擎,
更高性能的crun
crun是一个使用C语言编写的更高性能/更少内存占用的runc,下面介绍runc-cli本身所支持的功能(crun也基本是这些指令):
create创建容器。一旦创建了容器环境,运行时就与容器进程分离。必须依次使用start来启动容器。删除容器的定义。
exec执行正在运行的容器中的命令。
list列出已知的容器。
kill向容器init进程发送指定的信号。如果没有指定信号,则使用SIGTERM。
ps显示容器中运行的进程。
run创建并立即启动一个容器。
spec生成配置文件。
start启动之前创建的容器。一个容器不能多次启动。
state输出容器的状态。
pause暂停容器中的所有进程。
resume恢复容器中的进程。
update更新容器资源约束。
checkpoint使用CRIU保存当前运行的容器
restore从检查点恢复容器
想要看更加细致的options清单,看这
下面我们讲讲,源码安装:
apt-get install autoconf
git clone https://github.com/containers/crun.git
./autogen.shOCI image spec
这里,我们会讲到:
什么是image spec,spec当中的重点
如何自己从头构建一个container image
image的layer
容器的镜像都是由多个"layer"组成的,每一层可以新增,移除,或是改动文件;和git概念中的commit很类似(docker也有commit这样的功能)。layer是可以节省网络带宽和存储空间的:如果多个镜像共享layer,多个容器共同的从一个layer上去读一个文件,系统将只读和缓存一次(overlay2/aufs drivers)。这意味如果我们要节省磁盘IO和内存,我们可以尽力地让在一个节点上所运行的多个容器共享尽可能多的layer。
这种情况下使用动态链接的可执行程序是最节省内存开销的。
虚拟机镜像和docker镜像的结构差异
首先对于Docker而言,容器和镜像的差异仅是一个写入层(write layer),Docker镜像的组成实际是多个layer叠加在一个base layer上。这意味着:
- 如果我们使用基于同一操作系统的多个不同镜像,它们会共用同一个base layer
- Docker镜像本身不存在状态,所有对于容器的更改会写到上层的layer中
上面说的这些特性,都是虚机镜像所没有的,接下里让我们了解一下Disk image file formats:磁盘镜像
磁盘镜像是磁盘结构和常规数据的快照。一般来说,磁盘镜像是磁盘上每个扇区的逐位副本,但现在通常的结构是只复制已分配的数据来减少其体积。压缩和重复数据删除的技术被广泛用于减小镜像体积。Virtual disk images(比如VHD和VMDK)通常用于云计算,ISO镜像则通常用于数字取证
最小化容器镜像
大体上,我们本节涉及的主题,包括:
- 构造较小体积生产容器的基本技巧
- 实践:
- 构建一个cuda benchmark的较小镜像
- 构建镜像的check-list,pipeline
- 构造最小镜像的高阶技巧
在介绍一些更高阶的技巧前,我们先来回顾docker本身所支持的一些技巧:
- multi-stage builds
首先是我们运行一个程序,像编译器这样的toolchain我们实际是不需要的,我们只需要runtime-dep,即程序运行时所依赖的文件,下面是一个典例
FROM gcc AS mybuildstage
COPY hello.c .
RUN gcc -o hello hello.c
FROM ubuntu
COPY --from=mybuildstage hello .
CMD ["./hello"]- from scratch
结合多阶段构建,我们需要使用一个不包含无关依赖的最小基础镜像(基础镜像,指的是存放可执行文件的镜像),下面是一个典例:
FROM golang
COPY hello.go .
RUN go build hello.go
FROM scratch
COPY --from=0 /go/hello .
CMD ["./hello"]注意最后一句非常关键,不能写成CMD ./hello,因为这种写法默认使用的是bin/sh,但是我们没有这个启动器,另一方面,如果基础镜像是scratch,我们将无法进入容器(docker exec/kubectl exec),当然,除了scratch,我们也可以用Alpine版本的镜像,搭载了最小化的操作系统环境。
上面的例子演示的镜像体积最终结果如下:
- Single-stage build using the
golangimage: 805 MB - Multi-stage build using
golangandubuntu: 66.2 MB - Multi-stage build using
golangandalpine: 7.6 MB - Multi-stage build using
golangandscratch: 2 MB
再来,了解一些高阶的技术:
- Alpine(斟酌使用)
- Distroless+Bazel
- upx
- DockerSlim
大家可以试着装下alpine的docker images,不到5MB的磁盘占用
docker pull gliderlabs/alpine:3.4alpine也是一个linux发行版,但是体积比其他发行版要小许多,究其原因,分析如下:
- 只含有最小的必备依赖(可使用apk info查看有哪些)
- /var/lib/rpm
- systemd
- gconv(字符集)
- coreutils,glibc(使用的musl,这个过于小众),bash都简化了
- 没有预装python
那为什么有些场景还是不推荐使用Alpine呢?如果使用Alpine镜像作为运行C代码的基础镜像,同样存在一个问题,Alpine使用的标准C库并不是glibc,而是musl,这个库比起glic来说更加的轻量,一个比较关键的问题在于,musl的ABI接口和glibc的并不兼容,因此一个二进制文件想要动态链接musl并运行,需要被重新编译,这个过程其实可以通过带有alpine的toolchain镜像结合多步编译来解决。
FROM golang:alpine
COPY hello.go .
RUN go build hello.go
FROM alpine
COPY --from=0 /go/hello .
CMD ["./hello"]如果是C程序的编译,由于并不存在gcc:alpine,我们必须在alpine中安装C编译器:
FROM alpine
RUN apk add build-base
COPY hello.c .
RUN gcc -o hello hello.c
FROM alpine
COPY --from=0 hello .
CMD ["./hello"]What behind Distroless
- bazel
首先来看下,what behind docker build
小小的题外话:upx
UPX(ultimate packer for exe)是一种可执行打包器,可以用来压缩可执行文件的压缩器。通常来说,UPX可以减小程序和DLL的50-70%的体积。
原理相关内容:
- 依赖于NRV压缩库
- /src/stub包含了不同可执行格式的"解压桩",stub由汇编编写,并被“编译”成C头文件
- UPX的压缩算法是UCL
- UCL不需要为解压分配额外的内存,
想要更细致地了解UPX,可以看这两个链接:
AI-容器
shared gpu
其他容器软件
podman
Shifter containers for HPC
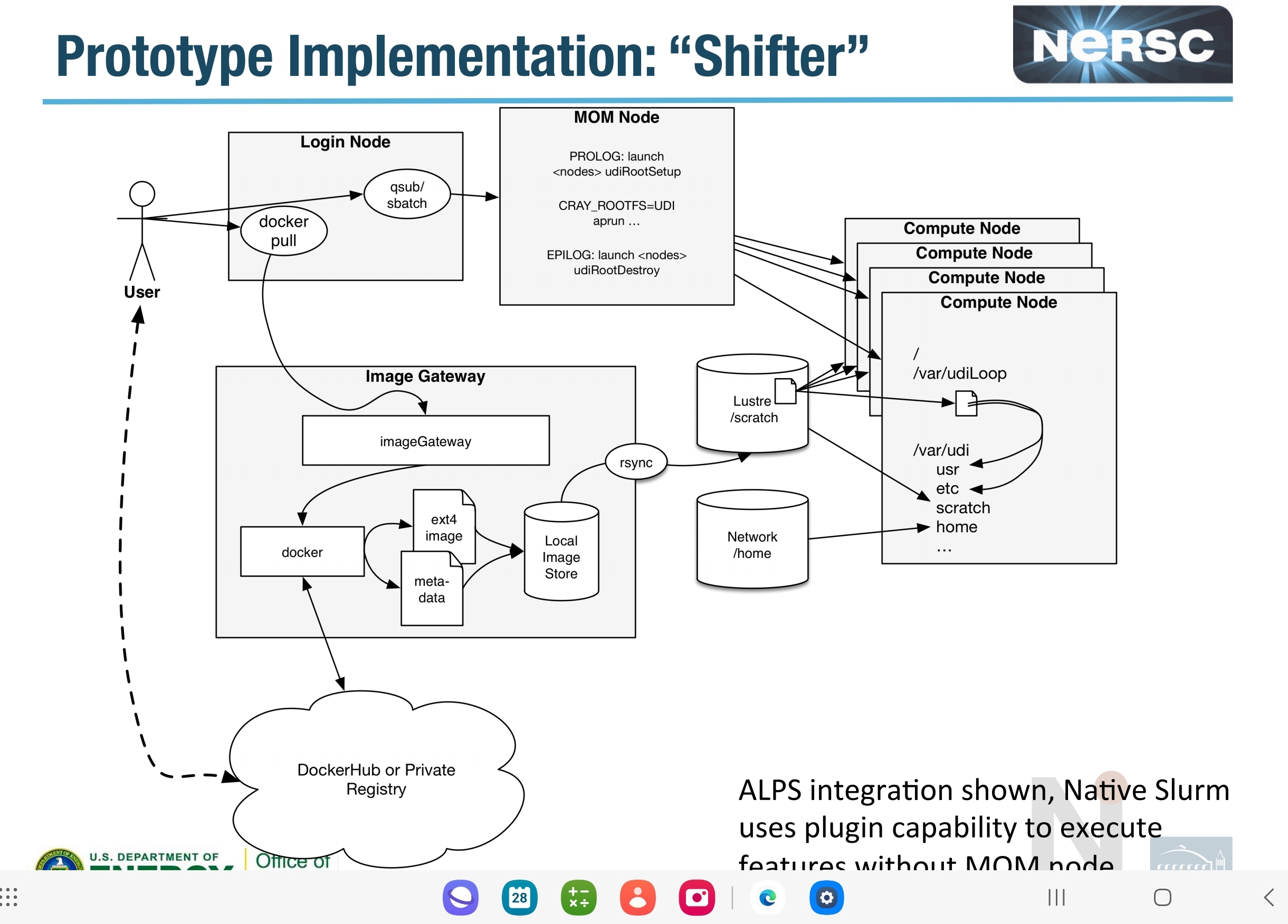
shifter是专为HPC应用设计的镜像引擎,它由几部分组成:
- 为应用创建执行环境的工具集
- 镜像网管系统,将镜像重新打包以适应squashfs
Docker4c
一个专门为C/C++开发设计的容器环境: blog 里面包含的内容包括:
- compiler
- cmake
- Conan
使用lxc文件系统
使用docker容器存在一些问题:
- 容器的根文件系统使用overlayfs,添加文件或者是删除文件,文件系统占用空间都不会减少
- 容器删除后,未提交的修改都会被丢弃,但不断提交会使得镜像体积膨胀
可以从Linux Container社区下载根文件系统tar包,解压系统到宿主机,使用hello world镜像创建容器,将该文件系统挂载到容器
调试器
自己开发ptrace based debugger
shell
下面介绍一些对于我工作,生活特别有意义的一些命令行工具(主要是unix类的) 首先会介绍一些存储,网络相关的通用命令,解决磁盘以及网络管理的硬需求
devbox(Nix)
官方说法“Reproducible development environments wherever you go“,这个概念接近于我前面提到的Portable dev env
'可重现'对于开发人员来说非常重要,不管是复现问题还是搭建开发环境再或者是部署软件栈复杂的服务(比如AI相关的)。显然,系统上安装什么软件应该是包管理器要做的工作,但是现实生活中,我们使用apt,yum或是什么其他的,总是会导致一样的命令在两套系统上得到不一样的结果(这个跟linux发行版有很大的联系)。
Nix可以帮助我们客服难关。本质上,我们要处理的所有环境相关的内容,都可以称之为“依赖”,在Nix的世界里,这些都是通过Nixpkgs来管理的。
大体来说,你需要知道的几个概念:
- Nixlang:一种函数式DSL,擅长通过已有文件派生新的文件,是一门lazily evaluated的语言
- Nixpkgs: 世界上最大的,更新最频繁的软件分发系统,使用Nix语言编写
- NixOS:一个可以完全采用声明式配置的Linux分发版本,充分利用了Nix语言和Nixpkgs
事实上nix的诞生还是比较早的,大概在20年前,可以在Initial version of nix找到:github.com/NixoS/nix/commit/75d788 
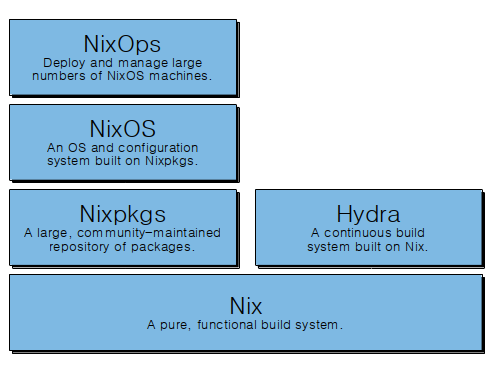
Nix软件栈:
有效的Nix学习资源
这些资源会指导你,帮助你达到:
- 学会使用nix构建自己的application以及library
- 查阅nix, nix-shell, nix-env, nix-store等cli的关键workflow
- 掌握nix workflow的工作原理
- 使用nix构建标准容器镜像
总览资源
Nix的学习材料实在太多了,这里推荐我认为最有效的:
- Nix pills:一个引导性的overview
- Nix wiki
- Nix手册:查看命令等
- nix社区
- awesome nix
细分资源
- 讲述nix-packaging的回答:unix.stackexchange.com/questions/717168
- 阐述nix的purity的帖子:reddit.com/r/NixOS/comments/xd0b7y/comment/io9vjcy/?utm_source=reddit&utm_medium=web2x&context=3
- 讲述nix-packaging的回答:nixos.wiki/wiki/Nixpkgs/Create_and_debug_packages
- 特定语言的构建帮助(最好用的):ryantm.github.io/nixpkgs/#preface
- 边讲边纠错的packaging教程:nix.dev/tutorials/packaging-existing-software
- 创建一个开发shell环境的教程:nix.dev/guides/recipes/sharing-dependencies#sharing-dependencies
卸载Nix
略
速览Nixlang
Nixlang的文档:nix.dev/tutorials/nix-language#reading-nix-language
内容非常丰富
- Nix代码完全由Nix表达式组成(嗯哼,scala)
- 任意Nix表达式的演算结果为一个值
- 使用nix repl进入nix的交互式运算环境
- nix-instantiate --eval xx.nix可以验算nix文件
- nix中的值可以是原生数据类型,数组,attribute sets或者是函数
- attrubute sets代表键值对
- 使用
<>作为查找路径,其值依赖于builtins.nixpath <nixpkgs>指向文件系统的路径- 除了表达式,还有杂质,杂质的存在目的只有一个:从文件系统中读取文件作为构建的输入
- Derivations是nix的核心特性:
- nix本身就是用来描述派生的
- nix通过运行派生来产出结果
- derivation本身是一个内置函数
Nixpkgs介绍
nixpkgs是一个巨大的软件库,我们先来讨论下常规的package manager如dpkg,rpm会遇到的问题:如果foo-1.0把程序安装在了usr/bin/foo,你没有其他方法在不重命名的情况下安装并运行foo-1.1(新的,旧的二进制文件)。为了解决这个问题,debian提出了alternatives系统。但这实际上也存在缺陷,比如你无法同时运行两个实例。所以我们又有了容器,这在一定程度上解决了问题,但从开发者的视角看,也存在问题:两个环境是隔离的,你怎么把两个软件栈混合在一起呢?
Nix认为这些问题是它处理的最好的地方,Nix管理系统的核心是/nix/store,Nix的派生存储在/nix/store/<hash-name>,Nix也有数据库,在安装的时候会存储在/nix/var/nix/db,这是一个sqlite数据库,用来跟踪derivations的关系,其中schema的关系也很简单:
其中一个表是将自增的整形映射到存储路径,还有一个依赖关系的表,将关系的依赖存储起来。
我们还需要留意profile:
ls -l ~/.nix-profile
如图我电脑上的nix版本是nix-2.1.3,我们在上述路径下看到的是Nix软件包自身的derivation,profile指向的是用户默认的版本,比如profile-4-link
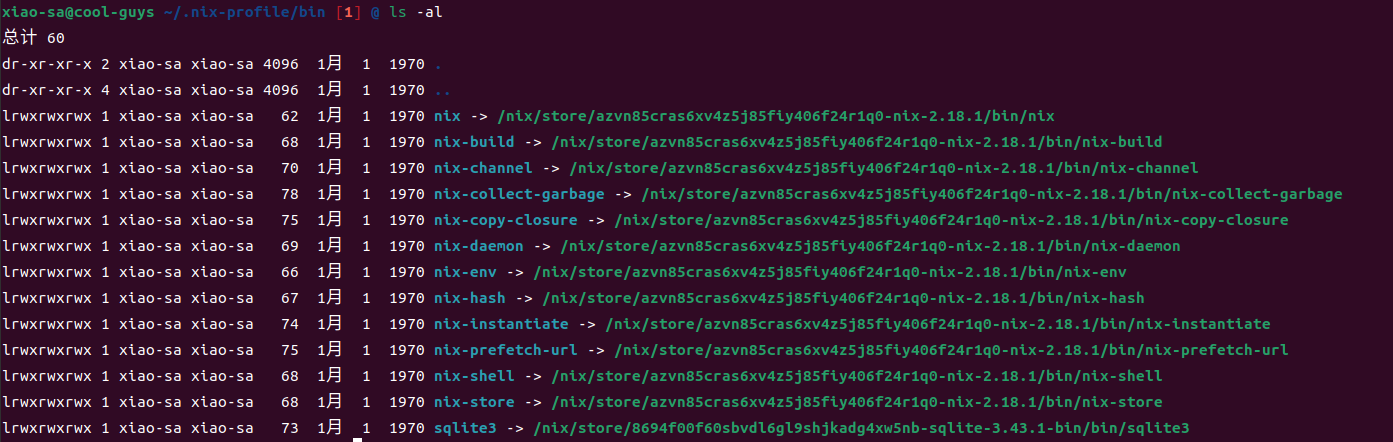
进入到bin目录下我们能看到二进制文件们都指向到了nix-store中存储nix本身的地方
安装了nix之后,~/.nix-profile/bin会被放到$PATH的首位置,从而系统原本的应用会被Nix接管
可以使用nix命令查看profile历史
nix profile history
# 下面为输出:
a-experimental-features nix-command
Version 1 (2023-11-15):
nix: ∅ -> 2.18.1
Version 2 (2023-11-17) <- 1:
sqlite: ∅ -> 3.43.1-bin
Version 3 (2023-11-17) <- 2:
hello: ∅ -> 2.12.1如果需要将nix的profile切换回第二版,我们可以使用
# 切换到上一个版本
nix-env --rollback
# 查看generations(并得知当前的generations)
nix-env --list-generations
# 切换到具体的generation
nix-env --switch-generation x其他常用命令
# 列举出显式安装的package
nix-env -q
# 查看可以获取的package
nix-env -qaP <pkg>在nix世界中,所谓package指的是一个Nix derivation:完成对某个项目的安装,Packages有一些标准化的attributes以及文件输出布局
nix-env是我们用来管理环境会用到的最多的应用,我们可以使用他来进行:
- 安装/删除/更新 软件
- 通过profile进行版本管理
下面我们来用nix命令探索一番:
# 查看nix提供的应用有哪些
ls -al ~/.nix-profile/bin
# 安装hello
nix-env -i hello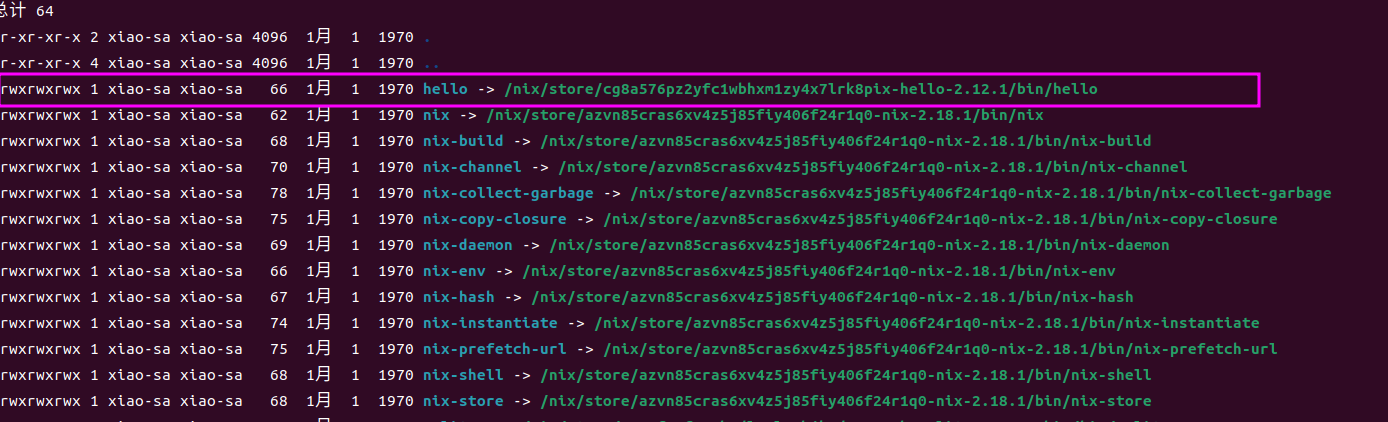
另外,使用nix-store,我们可以获取软件包之间的关系甚至是操纵它们的关系:
# 推荐使用hello做实验,最简单的一个package
# 获取dervation的依赖以及依赖dervation的包
nix-store -q --references <dervation>
nix-store -q --referrers <dervation>
# 树形结构打印
nix -store -q --tree <dervation>nixPkgs的工作机制
nixpkgs本身是一个软件集合,同时是一大堆的nix expression的集合。我按照自己的想法把nixpkgs的组成部分划分成了如下几个:
- cache.nixos.org: nixpkg的binary cache
使用Nix进行Packaging
derivation函数接受的集合至少需要包括三种attributes:
- name
- system
- builder
什么是.drv文件呢?
简单的例子请参考:nixos.org/guides/nix-pills/working-derivation
使用nix来完成packaging的过程,更加人性化的指导,可以从nixos.wiki/wiki/Nixpkgs/Create_and_debug_packages处获取,简单说说里面的内容。
对于许多开发者而言,最想要的无非是在任意系统上能够快速地,方便地重现开发环境,或者说是shell环境,为此我们需要做的其实是packaging 以及 distrubuting,我们以一个案例来介绍这件事情在nix世界中如何完成。
如同我们上面介绍的,我们使用nix工具主要是在和derivation打交道,在分发这件事上同样如此,我们要准备自己的derivation。
为此我们需要准备几个工具:
- stdenv.mkDerivation:该特殊函数会为你准备一个功能齐全的构建环境;另外你也可以在基础环境上扩展依赖;同样地,该函数会为你准备让你进行
./configure && make的builder - nix-shell:在你构造运行环境的过程中,得有一个调试/验证功能是否通过的过程,为此我们需要一个类似python的venv一样的功能,在nix生态中,这就是nix-shell
- callPackage:能够将package的集合中的默认值传递给构建derivation的函数
nix-shell的魔法
nix-shell会将derivation的依赖都构建出来,并启动一个derivation声明的环境变量的交互式shell环境,因此nix-shell本身就是用于重现环境的工具,如果path选项并未被提供,nix-shell会从工作路径中读取shell.nix文件,如果该文件不存在,则会读default.nix文件。如果路径是基于http或者https的,则会从对应路径下载一个tarball,当然tarball的最高层级必须包含default.nix。
如果derivation定义了shellHook变量,nix会在运行了source $stdenv/setup之后,运行该定义中的命令。同时我们需要重点介绍下wrapProgram,该功能的详细文档可以去nixos.org/manual/nixpkgs/stable/#ssec-stdenv-functions下查阅。
演示的内容
我们要做的事情,简单来说就是:
- 分发一个开箱即用的有一定复杂性的软件包(package)
- 分发一个有相同特点的应用(application)
需要一定的复杂性,我觉得Python的软件栈可以cover的住这样的需求(一个使用了混合编程技术的软件栈)。同时构建完成的标准是:能够在其他环境上快速地构建出一样的shell环境。
从nixpkgs中学习
我们从nixpkgs中找到几个有参考意义的derviation:
- dlib:pkgs/development/libraries/dlib/default.nix
- dlib-python:pkgs/development/python-modules/dlib/default.nix
- numpy
一个问题是,这些表达式的调用处在哪里?在pkgs/top-level/all-packages.nix,接着可以通过nix-build -A <pkg>验证build过程是否能顺利完成,以及通过nix-env -f . -iA <pkg>将pkg安装到profile中,最后,通过PR提交到官方仓
一个C/C++项目的构建
参照nix.dev上提供的教程,我们先来构建一个简单的计算类型的application: sort-bench
我们需要cover:
- 编译
- 安装:将关键的executable file保存起来
详情请到./envs/sort-bench目录下进行实践:
了解Python相关的nix表达式
在进入到实践之前,我们先来简单了解下nixpkgs给python语言提供的可以直接使用的表达式。首先是Python解释器的表达式可以在pkgs/development/interpreter/python路径下找到。
考虑到大多数人都是以使用Cpython为主,我们就来分析一下该目录下的项目构成(想要通过nixpkgs构建自己的包系统的各位可以考虑多去参考一下大粒度项目的default.nix,因为一般一个稳定的nix表达式是经过时间考验的并且考虑到很多平台因素的结果)。首先是cpython/default.nix,构建解释器的方法是stdenv.mkDerivation,这是因为Cpython解释器属于C语言项目,那default.nix必定有build c code的过程。
我按照自己的思路和认为是重点的部分将default.nix区分为这几块:
- python编译参数,列举几个比较重要的:
- pythonAttr
- passthruFun
- assert部分:注意到有许多断言语言,且都和
reproducibleBuild相关,以stripBtyecode为例,代表着如果要启用可重现构建,则必须启用字节码剥离 - 构建依赖项和配置:
- sysconfigdataHook:Python有一个特殊的模块:sysconfigdata,该模块是Cpython编译期间产生的,
- 构建命令:
- preConfigure
- postInstall
这里有个细节:可重现构建基本一定会影响到效率,这是因为优化的flag会影响到可重现性,具体可以参考社区的一个帖子:discourse.nixos.org/t/why-is-the-nix-compiled-python-slower/18717/9,这种时候就可以依赖override来进行项目定制化的改造了:
一段示例表达式:
let
pkgs = import nixpkgs { };
python38Optimized = pkgs.python38.override {
enableOptimizations = true;
reproducibleBuild = false;
self = python38Optimized
};
pyPkgs = python38Optimized.pkgs;
in
python38Optimized.pkgs.buildPythonPackage rec {
name = "python-example";
inherit src;
propagatedBuildInputs = with pyPkgs; [
numpy
];
nativeBuildInputs = with pyPkgs; pkgs.lib.optionals (pkgs.lib.inNixShell) [ipython];
}记录一些Python和nix的相关项目:
- on-nix/python
- dream2nix
- pynixify
- nixfied-ai/flake
Python-library构建模板
我们主要依赖buildPythonPackage函数来进行构建,其实现路径在pkgs/development/interpreterrs/python/mk-python-derivation.nix
对于Python library的构建,我们需要准备几个nix文件:
- pkgs.nix:这是指向内容地址的Nixpkgs
- default.nix:当前package的derviation(使用nix-build)
- shell.nix:将会import
default.nix,并覆写开发专用的依赖项 - release.nix:同样import
default.nix,并且生成多个release targets,其中就包括容器镜像
shell, application构建模板
我们一定需要一个可以调试的shell环境,为此,我准备了一个shell.nix模板
with import <nixpkgs> {};
with pkgs.python3Packages;
buildPythonPackage rec {
name = "mypackage";
src = ./path/to/source;
propagatedBuildInputs = [ pytest numpy pkgs.libsndfile ];
}使用nix构建包管理系统
到这里,是时候对nix构建出来的世界进行回顾和总结,并设想在自己的项目中,如何最大化地利用这一个工具。
我们先来研究一下Python和Nix结合的实践,从pynixify开始,首先安装方式,pynixify的安装方法是:nix-env -if default.nix,因此我们来分析一下pynixify的文件结构以及default.nix中的内容:
# 待补充我自认为的pynixify的核心设计原则:
- 扩展pkgs的python能力:自动构建pypi上有但nixpkgs上没有的python包,
存储相关的工具
lsblk
以树形结构列出所有块设备,输出信息中各列的意义介绍:
- NAME:设备名称,包括磁盘,分区,RAID,LVM
- MAJ:MIN:设备的主次设备号,用于唯一标识设备
- RM:是否为可移动设备,0表示不可移动,1表示可移动
- SIZE:设备大小,以字节为单位
- RO:是否为只读设备,0表示可读写,1表示只读
- TYPE:类型。
- disk 磁盘
- part 分区
- raid RAID
- lvm LVM(逻辑卷管理器)
- MOUNTPOINT:设备的挂载点,如果未挂载则为空
mount
e2fsck
用于检查和修复ext4文件系统的命令。
fdisk/parted
fdisk是Linux下的磁盘分区工具,可以用来创建,删除,调整MBR分区,下面列出常用方法: *
hwinfo
GDB介绍
GDB是GNU组织发布的UNIX平台下的程序调试工具,同样基于ptrace系统调用,使用监控程序检查和改变被追踪者的内存及寄存器。
gdb最重要的几个用途:
- 入侵程序runtime,读写数据
- 主要支持大多数编译型的语言
几个问题:
我的GDB workflow
GDB和Python到底什么关系?
GDB可以调试Python程序吗?咋做?
GDB对于Python开发者以及混编开发者最大的作用
gdbinit
- gdbinit是什么
- 使用gdbinit可以做到什么
GDB调试方法
- 直接启动进程调试 -> gdb [program]
- 调试core文件 -> gdb [program] [core] : 拿到core查看出问题的调用栈,寄存器信息
- gdb -p pid
常用命令
最好用命令:gdb -tui或依赖vscode以及gdb-gui等工具
设置断点
b <src:line>b func_name
删除断点:delete n(n代表第n个断点)
查看堆栈信息
- 打印最内层:bt n
- 查看所有线程:thread apply all bt
线程
- 转到某线程: thread thread_number
栈帧
- frame n
执行下一步命令(单步)
- next
gdb奇巧
- gdb --args
使用Python扩展gdb
case1:深入Python进程,做些恶作剧
./configure --with-python
# 在gdb进程中嵌入Cpython解释器
# 这个命令+python debug symbolsGDB的Python扩展能够给到我们什么:
- 在GDB中访问高层级的CPython解释器信息
- 在Python代码中访问GDB命令
- 定制化GDB commands
常用的访问Python信息的GDB命令:
- python [command]
- py-list
- py-bt
- py-up/py-down
- pylocals
- py-print
gdb -p <pid> -x gdb_commands.py
# 让gdb内的Cpython读取py_ext,获取新命令import gdb
# gdb.execute()是王道API,可以直接指定gdb去做任何事,有点像subprocess.Popen
gdb.execute()
# 那么,gdb里的 `call <expr>`又有什么讲究呢?
# 1.首先gdb会去查表,查符号表,找到所有函数的符号
# 2.查表会找到函数的对应地址,然后强制进程跳转到对应内存地址执行相应指令
# 3.configure with Cpython允许你call <C API>一些重要的C API
PyRun_SimpleString("<any python string>")- PyGILState_Ensure()
- PyGILState_Release()
case2:进一步封装C++对象,inspect them
语言binding
binding一般是由C/C++/Rust等语言暴露给脚本语言的接口集合,在C++语言中,一般就是给C++的类/函数创建一层封装,从而在脚本语言中能够import这些对象。
思考:混合编程的意义是什么
在《API design for C++》这本书中,作者的描述如下:
- 跨平台:脚本语言解释执行,从而它们的一般有中间形式
- 快速开发:重新编译/开发其实是很耗费时间和精力的,从REPL这种软件形式的诞生你也可以窥探一二
- 写更少的代码:在一个工具的工作生命周期中,通常工具的一些行为并非性能敏感的部分,用脚本语言实现这部分内容可以写更少的代码(比如命令行工具)
- 为行业专家提供支持:如pytorch, Pixar
Python生态圈中的binding工具
- cython
- cppyy(很特殊,需要拿出来单独讨论)
- pybind11
- PyO3
- ctype
binding的自动生成工具:
- binder
接下来会逐一解释这些binding工具中的典型,以及它们背后的原理
cython
pybind11 & Binder
clif
pyO3
pyO3是一个相对成熟的rust-binding库,大家一定会好奇这个工具是怎么work的。从reddit上摘录一个最高分的回答,大家可以去看看原问题:Can someone help me understand PyO3?i'm not sure hwo it works.
首先Python的核心实现-Cpython将python核心功能暴露到了一个名为libpython的库中,PyO3在这个库外部用安全的RUST API封装了起来。当你在Rust侧调用python时,实际上你在Rust进程中链接了libpython,有点像在浏览器中运行js。
cppyy
cppyy的特殊性体现在它本身是一个动态绑定的系统,他可以在运行过程中编译并运行c++代码,pypy原生就集成了cppyy(听起来就很像是通过cling来完成的,我只能说你想的很对)。 github上的cppyy仓实际是一个系统的前端部分,要将整个工具运行起来,我们需要先安装中间层以及后端的内容。
项目整体的结构长这样:
(A) _cppyy (PyPy)
/ \
(1) cppyy (3) cppyy-backend -- (4) cppyy-cling
\ /
(2) CPyCppyy (CPython)REPL
主题:C++的REPL实现
C++语言解释层
详情请关注:https://compiler-research.org/libinterop/
这里将一些个人认为重要的观点谈一下。
Python在科学计算以及范·机器学习领域内有很强大的生态,一个非常关键的因素就是其可交互性,结合其本身的胶水特性,Python在进行各种research的工作中可谓是神器。
依赖Pybind11这样的构筑在Python C-API上的C++ API,Python得以将native语言的高性能优势发挥出来。然而,这样的做法存在局限性,首先是这种binding方法属于静态的binding,效率上存在缺陷,另一方面是“trampoline functions”的问题:
在 Pybind11 和其他类似工具中,要在 C++ 类型和 Python 类型之间建立映射关系,通常需要使用类似于 trampoline 的方法。简单来说,trampoline 函数是一个中间层,负责将 Python 对象的调用转发到底层的 C++ 对象上。在 Python 中,当子类继承自父类时,通常需要将子类的对象向上转换为父类的对象,因此需要在 C++ 和 Python 中使用不同的 trampoline 函数来处理继承关系。这些 trampoline 函数通常会在绑定代码中生成,以确保 C++ 对象的函数在 Python 中的调用能够正确地处理继承语义。
然而,在某些情况下,这些 trampoline 函数可能需要重复定义和生成,以满足不同的继承关系。这些被称为 "redundant trampoline functions"(冗余的 trampoline 函数),因为它们可能会在代码中重复出现,导致代码变得冗长和难以维护。举个例子,如果一个 C++ 类型被多个 Python 类型继承,那么需要为每个 Python 类型都定义一个 trampoline 函数,这可能导致许多相似的函数定义。这是一种常见的问题,可能会导致代码的不必要的膨胀和维护成本的增加。另一方面,很多人认为动态绑定的效率一定比静态绑定要低,这实际上是个误区。 没错,反例就是cppyy。
cling介绍
C++是难以学习的一门语言,为了更好的掌握它,一些工具可能会帮到你很多。比如C++ REPL cling
相比于C++,Python会更容易学习,实际上这不单是语言复杂度的问题,我认为还有一个很原因是Python对于新人来说,可交互性会更好,自带REPL运行模式的解释器,而且这是一种常用模式,比如我们所熟知的Jupyter也是基于这种使用习惯所诞生的产品。REPL使我们可以更频繁地与Python语言本身交互,进行数据的探索,对于科学计算,数据分析类的应用而言,这至关重要,另一方面,这种探索也能快速提高一个人对于语法以及词法的熟练程度。
静态Binding生成工具Binder
binder是一个自动生成C++11项目的binding项目的项目。
原理介绍
参考文章https://blog.llvm.org/posts/2020-11-30-interactive-cpp-with-cling/
Cling支持完整的C++特性。包括模板,lambdas,虚拟继承。而Cling是在Clang和LLVM编译器架构上开发的一款应用。
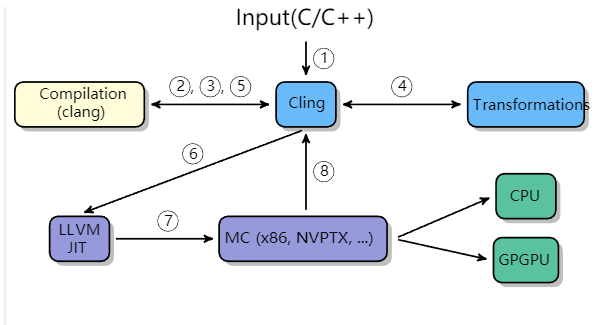
- 该工具通过交互式提示符或者一些REPL接口处理增量输入
- 将clang发送给其依赖的clang库进行编译,clang编译输入内容,将其转化为AST(②,③)
- 特殊情况下,AST要做进一步的转换(④)
- 将AST转化为LLVM-IR(⑤),LLVM-IR再次提交给JIT编译架构,去运行特定函数(⑥)
- 最终,生成的机器码(⑦)被提交给对应的处理硬件
C++本身的设计并没有考虑交互性,全局scope的声明执行,报告执行结果,实体的重定义是体现REPL用户友好性的最重要的三个特性。
常用操作
学习C++语法知识
jupyter notebook打开
启动对应的容器命令
docker run -it --network host --gpus all /bin/bash启动jupyter notebook
setsid jupyter notebook --port=8888 --no-browser --ip=0.0.0.0 --allow-root写CUDA
调试动态库文件
以dlib的matrix对象为例,演示如何调试库中的对象
- 以debug模式编译dlib,并且生成动态库二进制文件
像Python一样写use case
查看数据结构,数据类型
Profiling tools
libunwind
libunwind是内存分析工具memray所依赖的核心组件之一,
compiler
loopy介绍
AI assistance
chat-gpt
下面给出一些图例来说明chat-gpt在不同场景下对于开发的帮助(基于gpt-3.5)。