负载性能模型
- 软件世界中有很多benchmark(基准),如我们测试个人PC性能常用的软件,比如鲁大师
- 如何设计一个好的benchmark?
- 由于软件的运行特征本身太过于宽泛。想要了解一个负载的性能,我们需要先对软件性能本身进行建模
负载的特征
负载本身应该满足的基本条件:
- 具有通用的性能分评价指标
- 包含一个全量测试,能在任意系统上执行并给出性能指标
通用评价指标
- 性能分
- 能效分
通用特征
通用特征本质上都是一些时间序列特征
- CPU利用率
- 内存利用率
- 磁盘IO利用率
其他特征
Retired vs Executed
处理器最终执行的指令数通常会比程序本身所需要的多,这是因为Speculative Execution,对于常规指令,CPU会正常地发射指令,然后之前的指令会变为retired状态,但是对于推测执行的指令,CPU会避免直接将结果提交。当推测被认定为正确,CPU会释放指令,反之CPU会撤销错误指令对状态的影响,并不会retire相应的指令。
CPU利用率
一般来说我们认为CPU不在idle状态下的执行时间皆为有效时间。
UOPs
体系结构和微体系结构
- 体系结构是处理器处理器软件和硬件之间的接口,通过指令集来规定。简单概括:汇编程序员能够直接使用的功能。一般称为instruction set architecture,其典例有X86-32,X86-64,ARMv8,ARMv9
- 微体系结构是为提高处理性能而专门设计的结构,如cache, branch predictor, ROB。可以看出不是必需的。
静态微架构无关特征
任何程序都能被表征为一个汇编指令文件,换句话说,任何程序都能被表示为指令序列集合。统计指令序列的一些重要的值形成了重要的特征,其中:
- 不包含处理器微体系结构的信息
- 也不包含程序运行的动态信息
的特征被称为静态微架构无关特征:
- 汇编码的基本块数量
基本块的含义
int foo(int x) {
int y = x + 1;
int z = y * 2;
return z;
}上面的代码经过编译后,生成的汇编码如下:
foo:
movl %edi, %eax
addl $1, %eax
leal (%rax,%rax), %eax
retq基本分类方法
首先需要明确的是,以衡量性能/能效作为前提,则测试对象是SUT(system under test),是运行负载的整套计算机系统。
给不同的任务进行分类实际上是一个困难的过程,因为计算任务的特征可以在硬件,业务目的等不同维度体现,但这些维度本身不好归结为一套评价体系,另一方面,在单一维度中,一个任务的分类方法也无法直接量化(举个例子,一个任务完全可以即是任务密集型又是内存密集型,任务在这两者上的压力都足够大,但由于CPU和RAM完全是不同的部件,不存在直接量化的边界),从这个角度看,使用聚类的思路来对任务重新分类是一个更好的思路(但是注意,这必须以通用的性能指标作为前提)。因此下面的分类更多是从基准设计的角度出发,以人的经验构成的分类标准。
按照计算机组成部件分类
- CPU密集型
- 内存访问密集型
- 磁盘访问密集型
- 网络密集型
- 加速器设备
按照业务分类
这一项也可以参照openbenchmarking.org提供的"suites"来分类。
- 操作系统类测试
- 数值计算/HPC
- 语音/视频处理
- 编译器
- 数据库操作
- web test
- 文件压缩
- 加密
- 图形化
按照计算业务进行分类
- CPU负载
- 单线程负载
- 多线程负载
- 集群负载
- 延迟敏感
- 批处理
- 微服务
- 流式处理
- 批流融合
- WASM
- GPU负载
- CUDA流式负载
- CUDA非流式负载
采集,分析工具
实际案例
按照当前设计的分类标准,对一些负载进行归类,得出该表:
| 基准名 | 分类 | 简述 | 性能指标 | 获取链接 |
|---|---|---|---|---|
| uarch-bench | CPU密集型, |
吞吐量瓶颈
一台全闪存服务器上做大量的文件IO,性能瓶颈在哪,可能的点:
- SSD本身的承载能力
- 做IO的逻辑核数
DynamoRIO
我们可以利用二进制打桩工具DynamoRIO研究,分析benchmark代码,帮助我们找到和理解负载的性能特征。
overview
运行时,DynamoRIO工具和应用的关系如下: 
想要理解整个DynamoRIO的工作原理可以看dynamorio.org/overview.html,无论是使用虚拟机模式还是native模式运行的应用,过程数据都不会受到任何干扰。
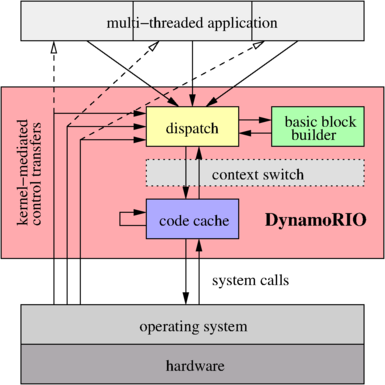
追踪和分析应用
首先,追踪和分析应用使用的是drcachesim组件,包括两个组成部分:追踪器drmemtrace以及分析器analyzer。前者采集信息,包括各线程/子进程的内存访问,而analyzer则可以在线/离线地读取痕迹,并给出分析,分析器默认会模拟目标系统的缓存设备来运行程序。
值得注意的是,analyzer的设计扩展性非常强,你可以:
- 自己实现模拟器,包括CPU caches,TLBS,页缓存(extending the simulator)
- 构造自己的分析工具
分析工具的包含内容与妙用
DynamoRIO API
提供了如下API:
- 内存分配:包括线程私有和线程共享
- 线程的本地存储空间
- 本地线程栈空间
- 简单的互斥锁
- 文件创建,读取,写入
- 地址空间检索