编译与链接
引子
pyx文件的导入
后续补充
编译过程
编译能被分为几个阶段:
- 预处理(gcc -i
<input file>-o<output preprocessed file>.i)- include the files
- 将#define定义的变量转为constants
- 将宏定义转化为对应的代码
- 包含/去除代码的指定部分(#if/#elif/#endif)
- 语言分析(linguistic anlysis)
- 词法分析
- 语法分析
- 语义分析
- 汇编(assembling):转换成对应CPU的汇编码(gcc -S
<input file>-o<output assembler file>.s) - 优化
- 当源码对应的汇编码生成后,优化操作开始,首先要做的就是最小化寄存器的使用
- 以及删除不执行的代码
- 代码发射(code emission)
- 最终,编译器需要生成产物:对象文件,这个阶段,汇编码汇编转为平台特定的机器码,并被写入指定位置的对象文件中
obj文件的的属性
- 对象文件的基础元素是符号(内存地址的引用)以及段,在对象文件中,最常见的内容是代码(.text),初始化了的数据(.data),没有初始化的数据(.bss)
- 目标文件并不会包含堆/栈中的数据,在程序的内存map中,这两部分的内容完全取决于运行时,而且并没有程序特定的初始位置;
- 目标文件对程序的.bss段的贡献较少
- 源文件与目标文件是一对一的
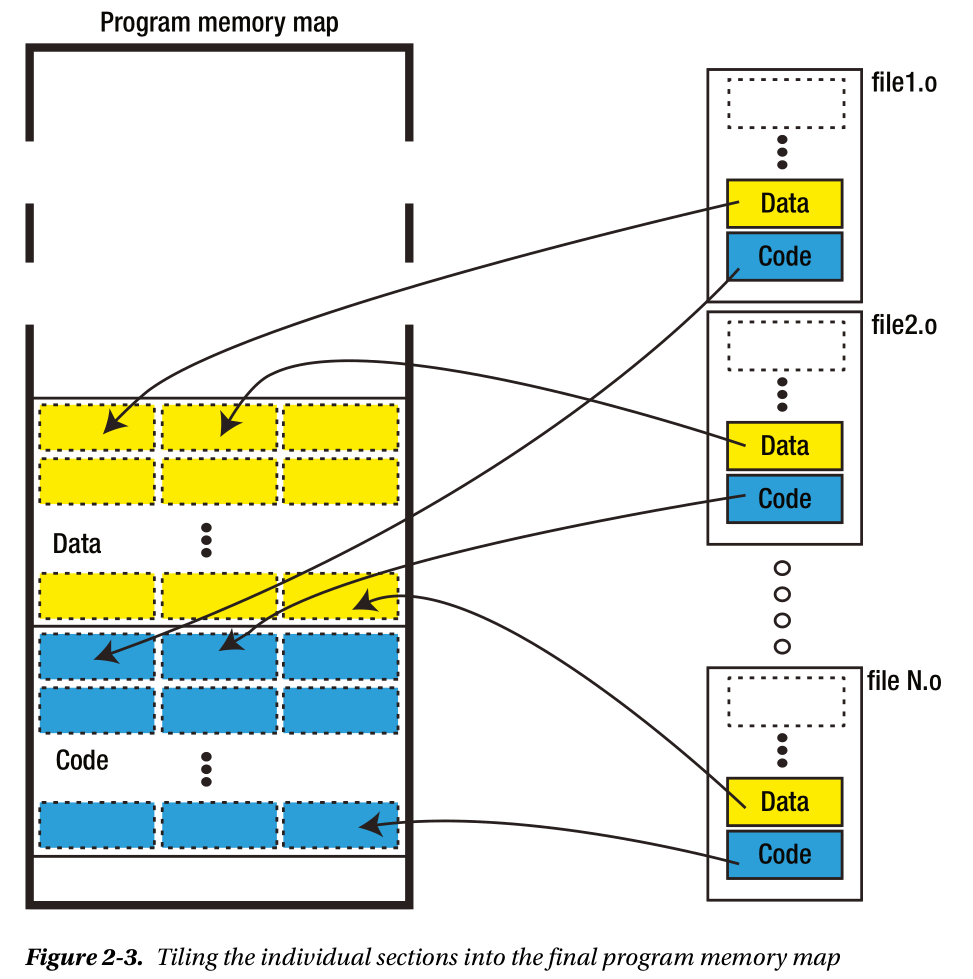
编译过程的局限性
为什么,编译过程要和链接过程分开呢?简而言之:将段组合在一起(特别是代码段)是非常困难的过程;其次,代码复用。
- 源文件之间一般有如下两种联系:
- 函数调用:不再赘述
- 外部变量:常被多个模块共同引用的变量,经常被用作维护为一种状态(C语言常用)
- 为了要对上述两种符号的访问,它们的地址必须要被知道,这些地址的实际值在各个独立的对象文件被组织成正儿八经的程序段之前通常不能确定下来,这个时候,这些引用都被称之为“未被解析的引用”。
关于链接
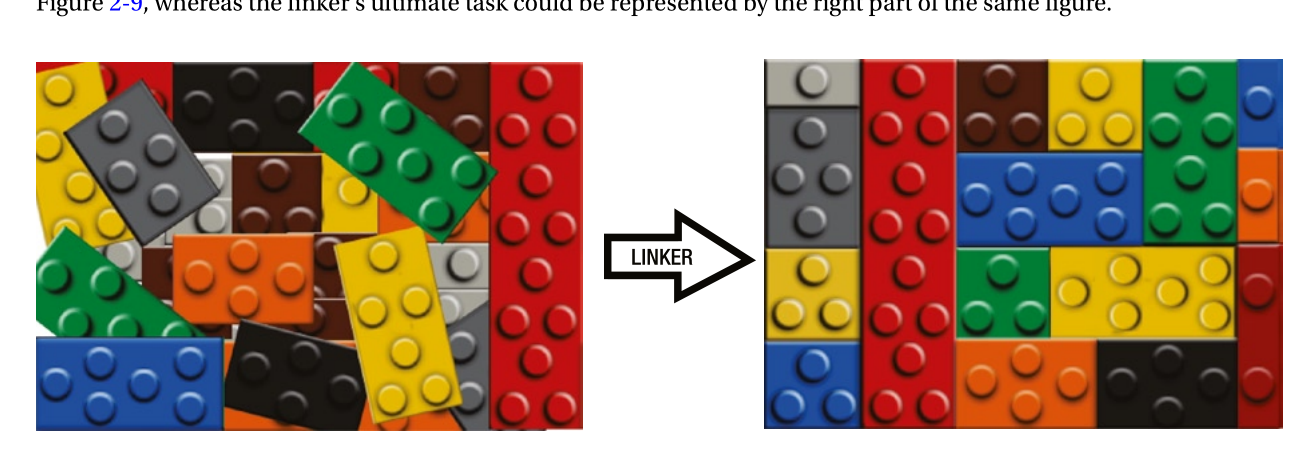
可执行文件的属性
可执行文件包含目标文件所包含的所有东西(.text, .data, .bss...),而后,经过对目标文件的整理,完成resolve reference
需要提到的是,除了编译单元对应的目标文件,有一段对启动程序而言非常重要的目标代码也被整合进去了,这段被链接器存储到了程序内存映射视图中的顶层:
- crt0
- crt1
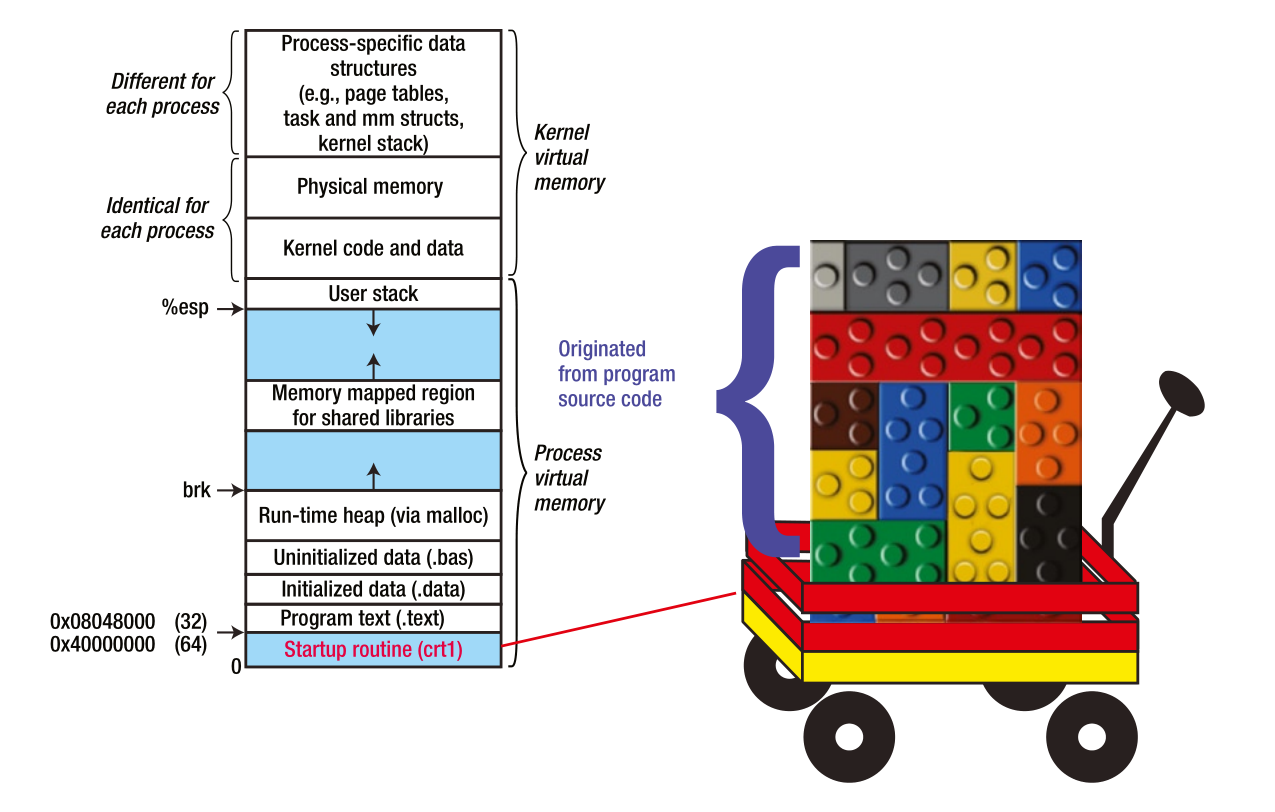
这段额外的代码,是决定二进制文件是可执行文件/动态库的关键:动态库是没有这段代码的。
程序执行阶段
shell的重要性
我们一般通过shell来执行可执行文件,linux环境下,shell执行某个可执行文件,通常需要通过fork自身:shell进程本身的内存映射会被复制成为新进程的内存映射,环境变量也会通过这种方式传递给新的进程。实际上,新进程创建后不久shell原本内存中不被需要的数据会被覆盖写入。
loader的职责
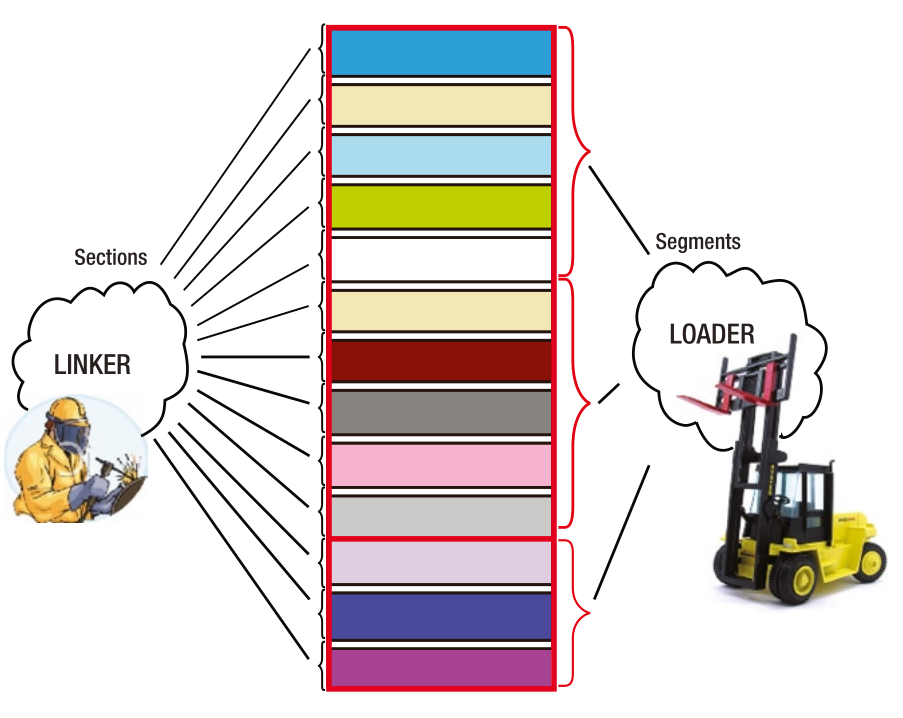
即创建进程的内存映射,运行时将可执行文件中的不同sections合并成内存映射的segments;从运行时的角度去观察:
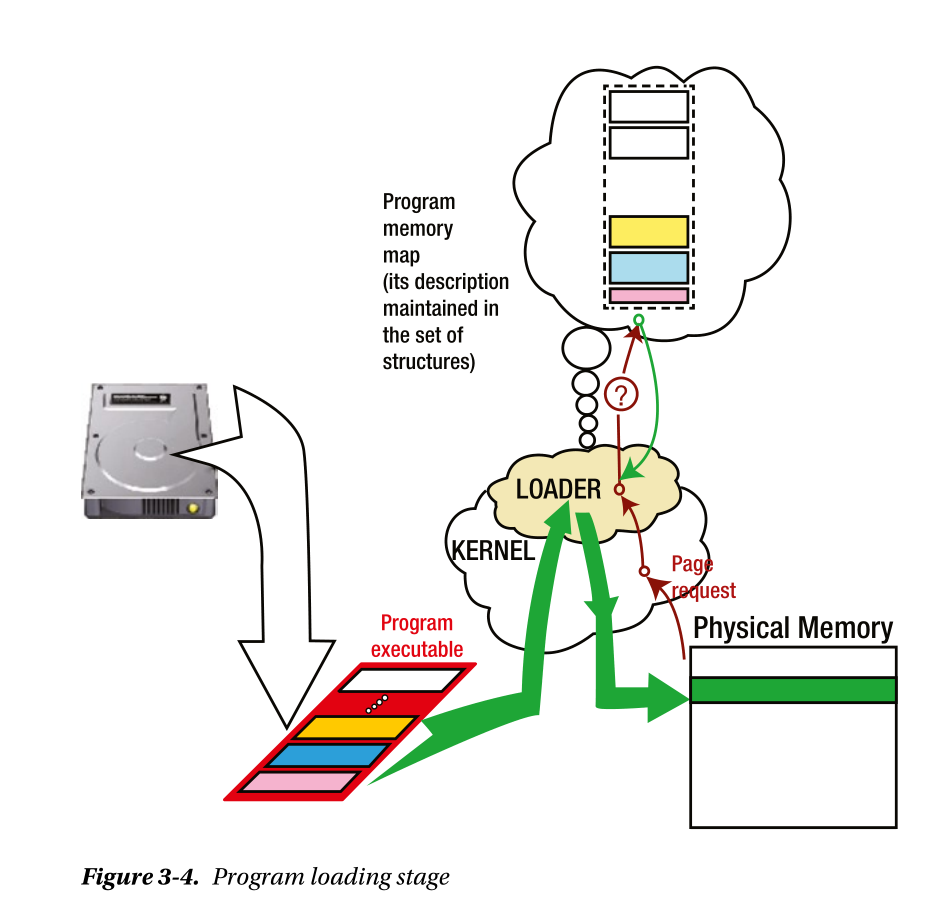
执行阶段分解
#include <stdio.h>
int main(int argc, char* argv[])
{
printf("Hello, world\n");
return 0;
}Disassembly of section .text:
0000000000000530 <_start>:
530: 31 ed xor %ebp,%ebp
532: 49 89 d1 mov %rdx,%r9
535: 5e pop %rsi
536: 48 89 e2 mov %rsp,%rdx
539: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
53d: 50 push %rax
53e: 54 push %rsp
53f: 4c 8d 05 8a 01 00 00 lea 0x18a(%rip),%r8 # 6d0 <__libc_csu_fini>
546: 48 8d 0d 13 01 00 00 lea 0x113(%rip),%rcx # 660 <__libc_csu_init>
54d: 48 8d 3d e6 00 00 00 lea 0xe6(%rip),%rdi # 63a <main>
554: ff 15 86 0a 20 00 callq *0x200a86(%rip) # 200fe0 <__libc_start_main@GLIBC_2.2.5>
55a: f4 hlt
55b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1).text的_start函数对应的源码是:
int __libc_start_main(int (*main) (int, char * *, char * *), /* address of main function */
int argc, /* number of command line args */
char * * ubp_av, /* command line arg array */
void (*init) (void), /* address of init function */
void (*fini) (void), /* address of fini function */
void (*rtld_fini) (void), /* address of dynamic linker fini function */
void (* stack_end) /* end of the stack address */
);这个函数的目标就是为了后续执行准备相关的参数。
再看反汇编码的554行,调用了__libc_start_main函数:
该函数为执行准备相应的环境,包括:
- 启动程序的线程
- 调用_init()函数
- 注册_fini()函数
重用概念
静态库的重用
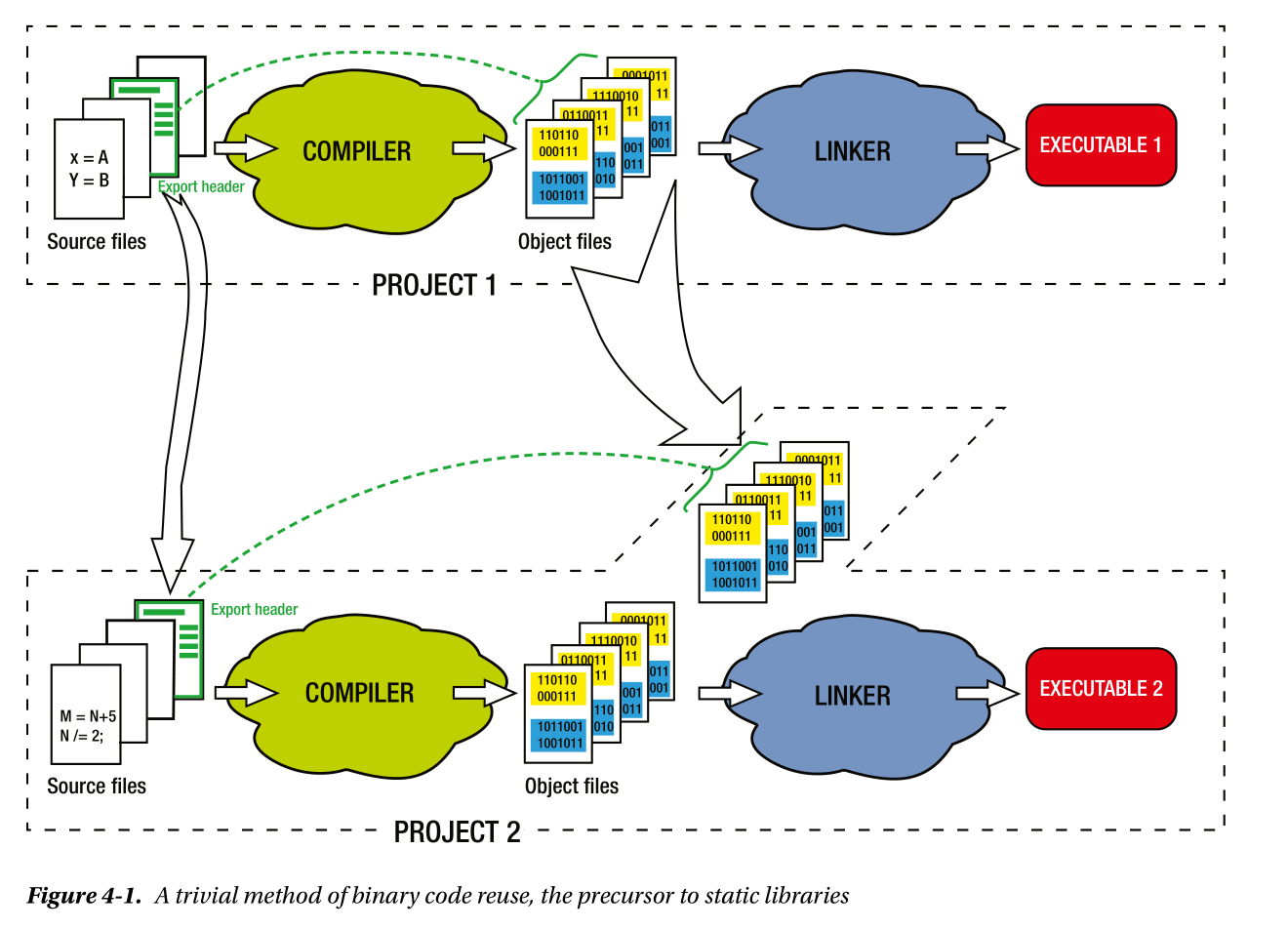
你想要使用已存在项目A的一些组件/功能,假设你拥有该项目的对象文件,那么你还需要满足一个基本条件:即目标文件中包含导出的头文件,头文件中的定义/声明可供你做“说明书”。
上图中就是重用的典例,使用头文件,目标文件,你可以在自己的项目中对其他项目的资源进行引用,再通过链接器重新生成可执行文件。显然这种方法会让交付变得稍微麻烦,因为一个模块大多包含多个目标文件,如果能将其打包成一个统一的“库”,那事情会变得更简单,因此就有了静态库(static library)。
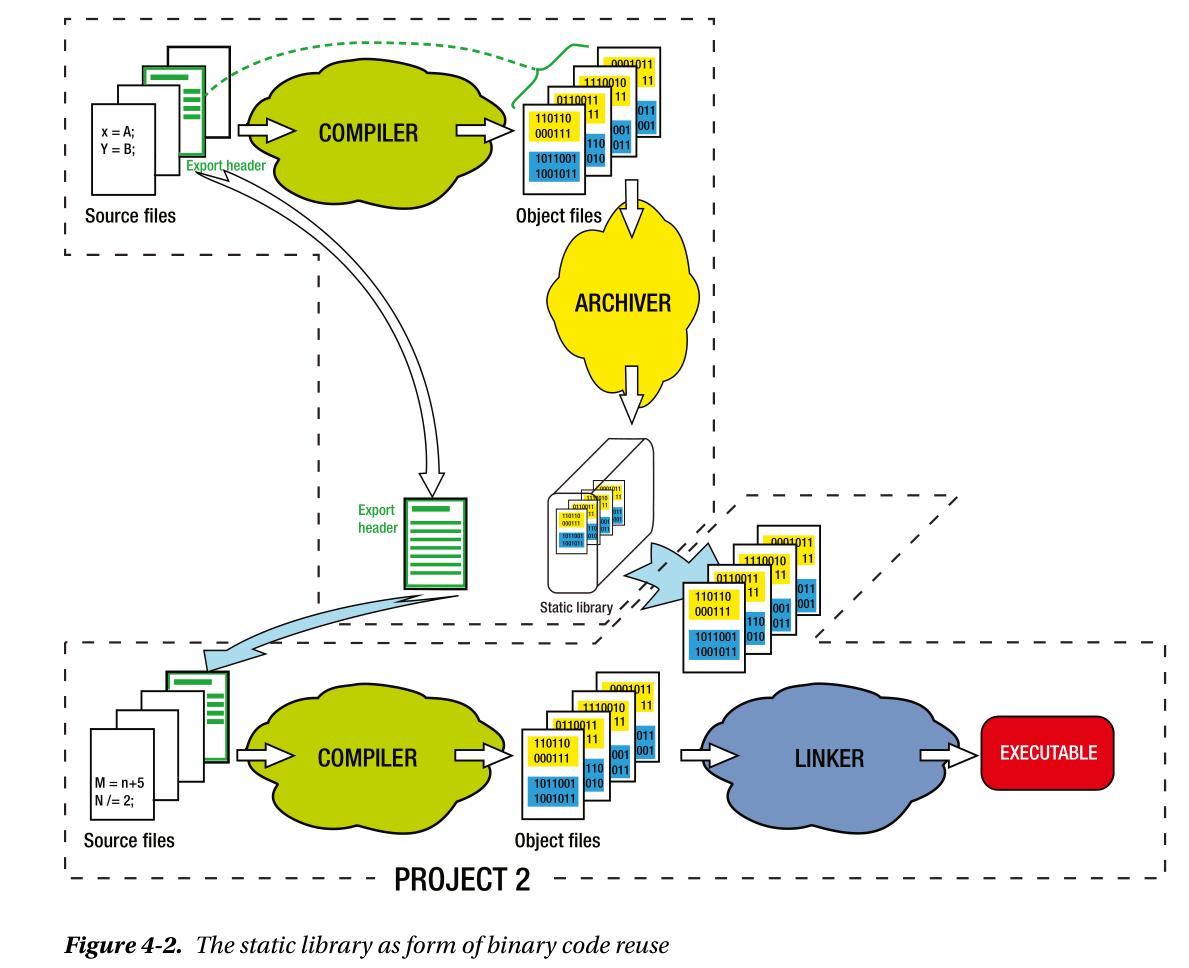
这里就存在几个问题:
- 链接器能够理解被打包好的库文件嘛?
- 打包的过程可逆吗?
动态库
动态库的出现与多任务操作系统的出现有密切联系:因为多项进程对同一控制例程的复用成了刚需。动态链接/动态载入应用而生。想象一下多进程能同时共用一个run-time吗?显然这样会冲突,但在内存映射中,.text,即代码段可能是能够被共用的,如果多个进程共用一个代码,那能省下不少运行时的内存占用。
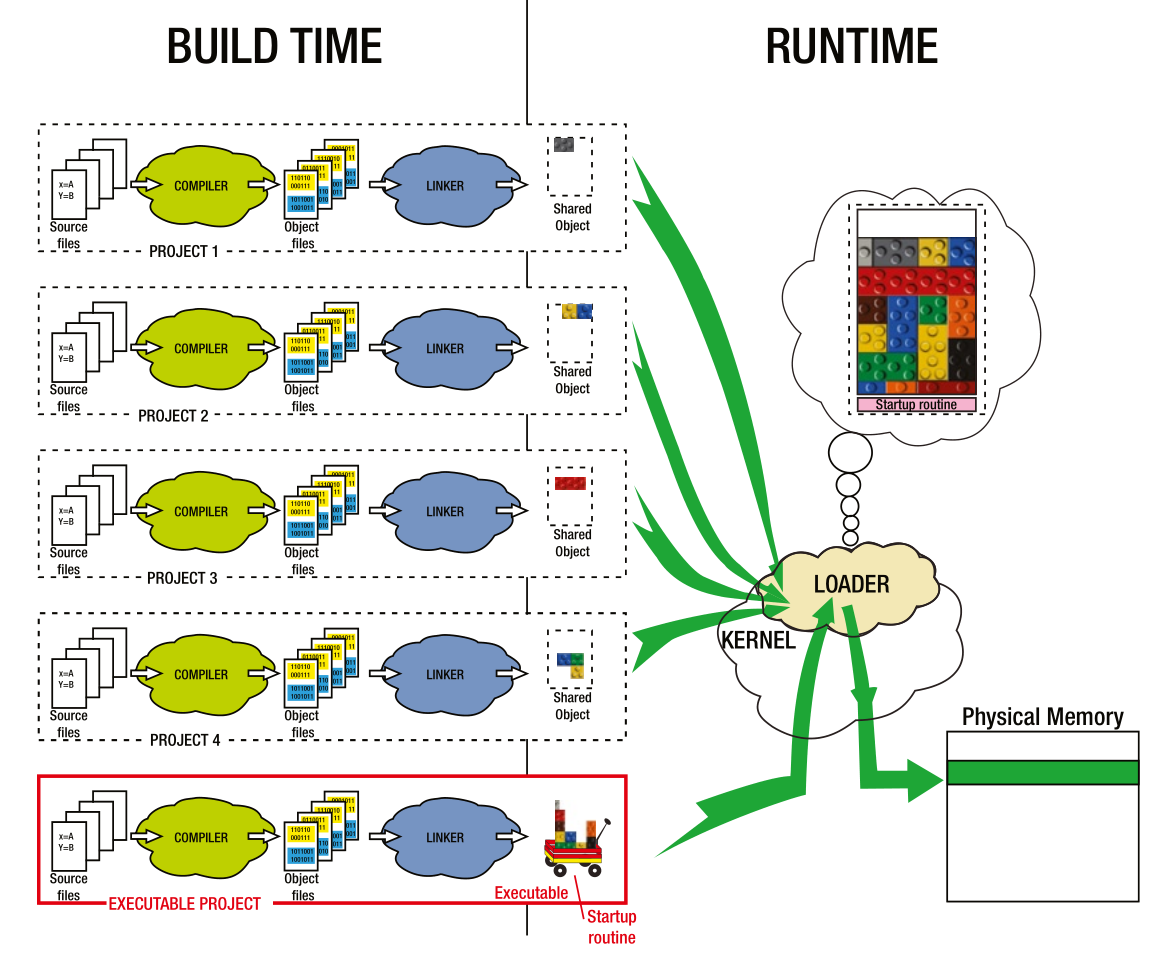
创建动态链接库
- 动态链接库和可执行文件非常接近,唯一区别是动态库是没有启动例程的
- windows下,构建动态库要求所有引用能被搜索到,如果动态库调用了其他动态库的函数,那么链接器在编译期必须找到对应的符号;
- linux下会更灵活,允许一些
- 链接库能够互相引用
ABI
听名字——application binary interface。你可能会想,这个ABI应该就是在编译/链接过程当中由源码生成的符号的集合,特别是一些函数的入口,不错。
ABI主要在动态链接中被提起:
编译阶段,client binary实际上是连接了被导出库的ABI,在编译阶段,链接器是不会关注函数的实现内容的,只会确保引用库导出了对应的ABI。
DLL(Dynamic-Link Libraries)
在DLL中调用一个函数有两种方法(或者说动态链接也只有有两种):
- compile-time动态链接,一个模块显式地调用DLL函数
- run-time动态链接,使用LoadLibrary和LoadLibraryEx来在软件的运行时载入DLL的方法,当DLL的内容被load进内存后,调用者再通过GetProceAddress函数来获得被导出DLL的函数。(动态链接)
DLL和内存管理
每个进程载入DLL文件的时候,会将其地址段映射到进程的虚拟地址空间中,系统为每个DLL文件维护了引用计数值,当一个线程载入DLL,引用计数值加一。进程结束/计数值为0时(限定为运行时的动态链接),DLL的内存映射就会被清空。
就像其他函数一样,被导出的DLL函数会在被调用的线程中执行,因此:
动态链接的优势
- 多进程共享一份内存,节省空间;
- 当DLL文件中的函数发生改变时,对他进行链接的进程无需重复编译或者重复链接:当然,有前提,便是函数的签名不能改变。与此对比,静态链接的对象文件需要重新链接;
- 程序补丁
- 提供给其他语言调用
对比动态库和静态库
链接的内容
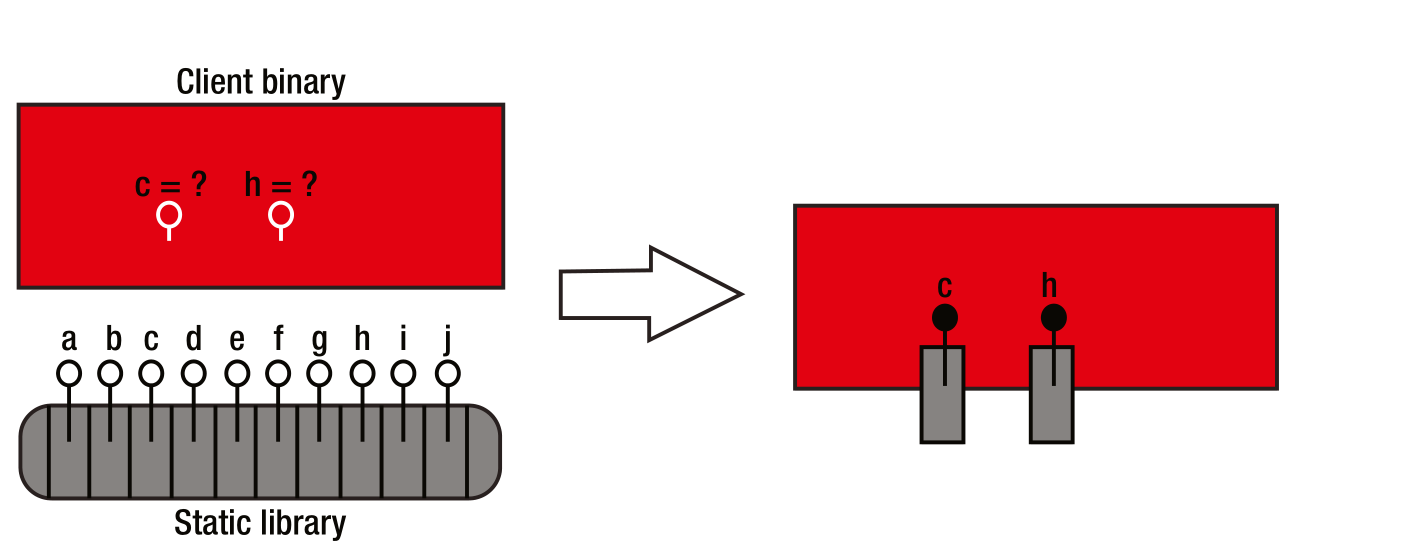
简单来说,静态链接,只取所需,链接器会从相应的目标文件里取出需要的符号以及实现,如上图所示。
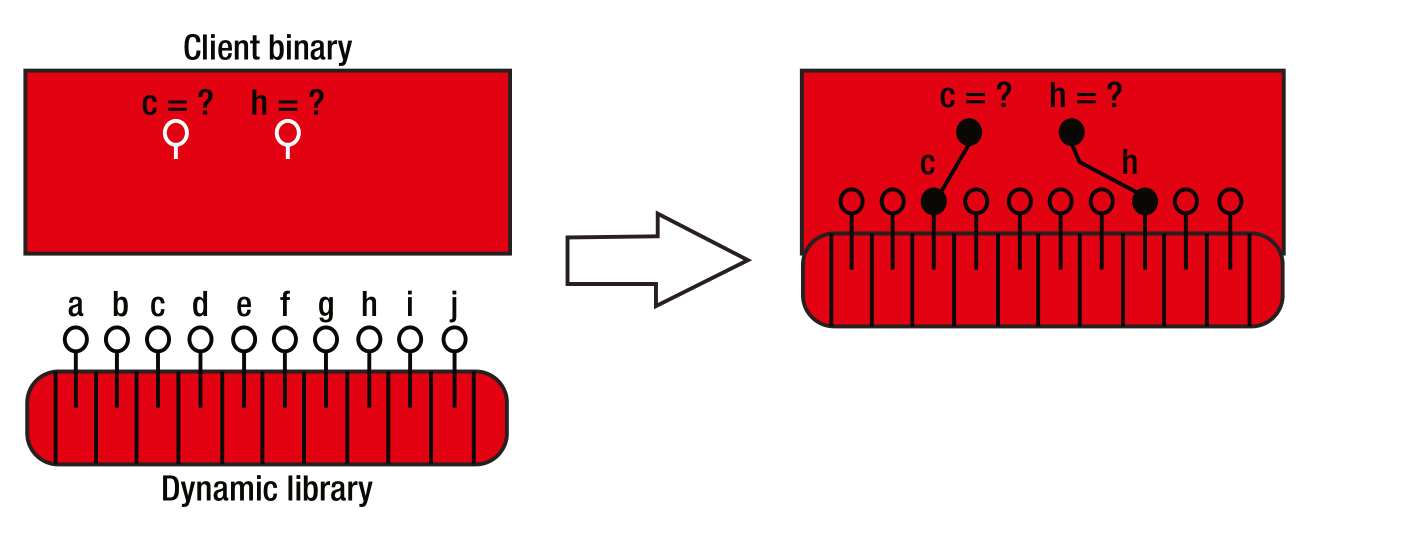
与之对比,client bin链接动态库时,整个动态库都会被链接入可执行文件中。
符号
对象文件中引用对象的代称,包括:
- 函数
- 全局变量
动态链接
- 运行时链接
- 函数/数据实际存在于共享对象当中
- 编译器会给最终的对象文件创建符号引用
静态链接
- 外部库符号的内容会被编译到最终的对象文件中
动态库设计
编译器和链接器提供了非常丰富的flag用以构建不同场景下的动态库。
Linux下创建动态库
常用flags:
- 编译器的-fPIC
- 链接器的-shared
演示一下:
gcc -fPIC -c first.c second.c
gcc -shared first.o second.o -o libdynamiclib.solinux下的一般约定是:动态库一般带前缀lib,同时文件扩展名为.so
二进制接口的设计
C++存在的问题
- 问题一
与C语言不一样,C++的链接器符号给链接器设计带来了很大的挑战,因为需要考量如下两个因素:
- C++的函数很少是独立的,它们一般会伴随着一些代码实例(这是OOP必须面对的问题),比如说,方法就是类的函数,而类属于某个namespaces下,当template参和进来后,情况变得更复杂,为了确立独一无二的函数,链接器必须将函数附带的信息找到并给到函数的入口
- C++的重载机制允许同一个类有多个同名的不同方法,同返回但不同输入。为了唯一地定义函数名,链接器必须将输入的信息附加给函数符号
由于上述问题,